前言
AI 技术的飞速发展,正改变着我们生活及工作的方方面面。而在视频领域,近日 字节跳动 新发布了一款令人振奋的新模型: AnimateDiff-Lightning ,无疑是一次革命性的突破!
项目介绍
AnimateDiff-Lightning 是一款基于深度学习的视频生成模型,只需 4-8 步的推理,就能生成出质量极佳的视频,从而引起了广泛关注。
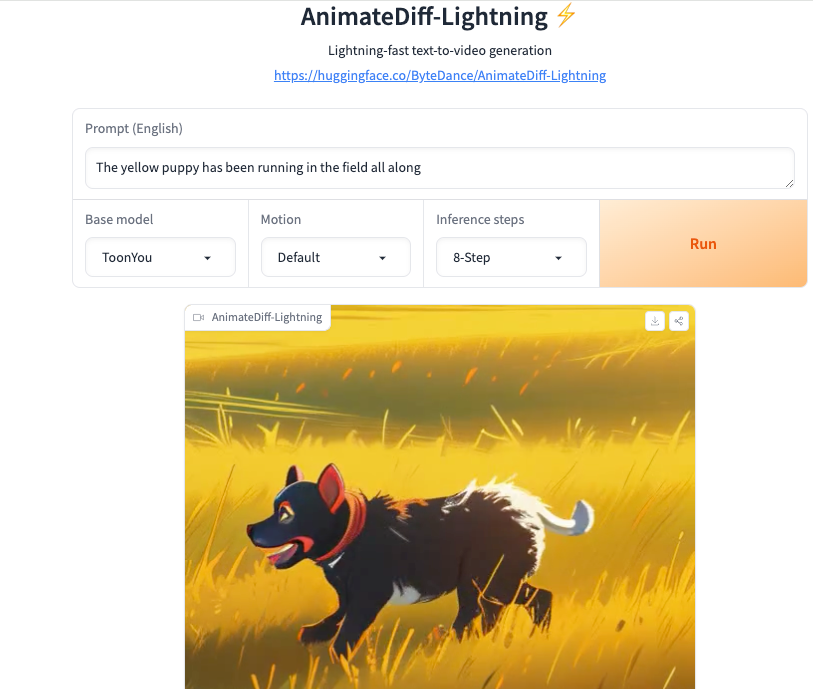
该模型采用了渐进式对抗扩散蒸馏技术,恰似可以使用闪电般的快速视频生成。同时字节研发团队也提出了跨模式扩散蒸馏,提高蒸馏模块泛化到不同的风格化基本模型的能力。这一突破性进展也为 AI视频生成领域 带来了新的可能性。尤其是与 Contorlnet 的配合下,视频转绘 的工作流程有望迎来全新的升级。

此外,字节团队还开源提供了对应的Comfyui工作流程,为开发者提供了一套完整且高效的解决方案。
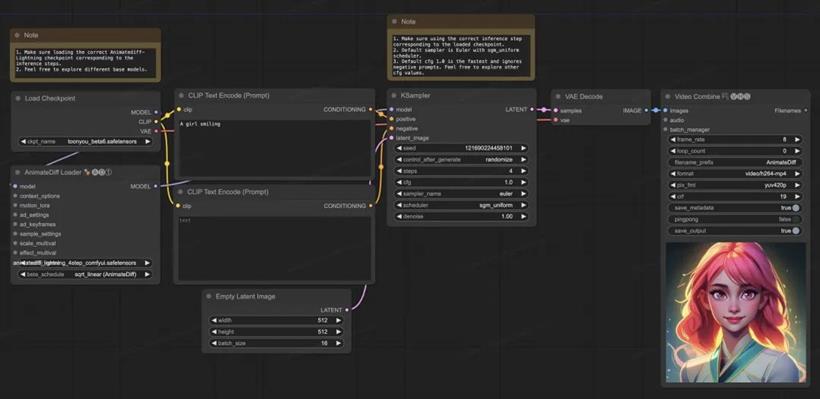
值得一提的是,AnimateDiff-Lightning模型 是从 AnimateDiff SD1.5 v2 中精心提炼而来,包含了1步、2步、4步和8步提炼模型。其中,2步、4步和8步模型的生成质量表现尤为突出,为用户带来更加优质的体验。
除了模型本身的优秀表现,字节还建议使用运动LoRA来进一步提升视频质量。运动LoRA能够产生更强的运动效果,建议选择强度在0.7~0.8之间的运动LoRA以避免水印等干扰因素。
HuggingFace:https://huggingface.co/ByteDance/AnimateDiff-Lightning
DEMO体验:https://huggingface.co/spaces/ByteDance/AnimateDiff-Lightning
 主要特色功能
主要特色功能
• 仅需 4-8 步推理,就能生成高质量视频,速度快效果好。
• 与 Contorlnet 配合,提升视频转绘工作流程。
• 提供 Comfyui 工作流程,方便开发者使用。
• 推荐使用运动 LoRA,增强运动效果
应用场景
AnimateDiff-Lightning 模型 的应用场景可以很广泛,不限于影视制作、广告宣传、教育培训等多个领域。
总结
总的来说,字节的 AnimateDiff-Lightning 模型为 AI 视频生成领域注入了新的活力,为开发者提供了更多的可能性和工具。随着技术的不断发展,我们有理由相信 AI 视频生成领域的未来将更加辉煌!


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






