

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

阿里巴巴绝对会是世界大模型舞台上一个重要的选手。3个小时前,它发布了最新的推理模型 QwQ-32B。注意,是32B。早上醒来迷迷糊糊,以至于我觉得可能是自己看错了,参数居然如此之小。但各种各样的基准测试证明,拥有 320 亿参数的模型,其性能可以与具备 6710 亿参数的 DeepSeek-R1 媲美。这也就意味着,我们可以在更小的设备上,运行一个更好的推理模型。QwQ-32B 已经采用 Apache 2.0 协议开源。
Qwen 团队在 blog 中说,他们发现 RL 有可能超越传统的预训练和后训练方法来提升模型的推理能力。QwQ-32B 就是最直接的证明。这条路如果能走得通的话,那阿里巴巴也许已经为大模型行业摸索出来一条通往 AGI 的路径:用强大的基础模型叠加大规模强化学习。
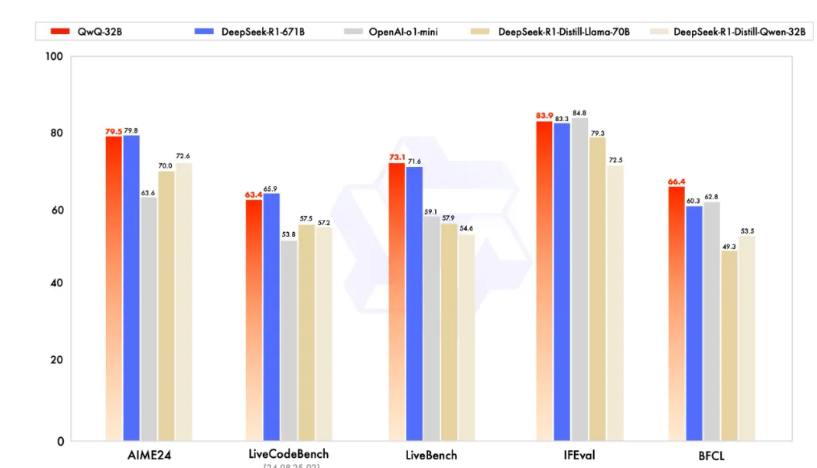
去年 11 月底,阿里巴巴曾经发布过 QwQ-32B-Preview 的推理模型,被认为是少数几个能够与 OpenAI 的 GPT 模型相媲美的模型之一,不过,那只是Preview版本,没有引起特别大的轰动。这些天,等他们发布正式的模型。这一天,终于来了。更小却更强大的模型。
按照以往的经验,部署 32B 模型,拿一台 24G 显存、16核 CPU,64G 内存机器就够了。它让本地部署好的推理模型真正成为可能。我不知道怎么表达现在内心的震撼,不可思议。我们将迎来需要更少GPU来运行更强大的推理模型的时代。如果在这个基础上,蒸馏出来更小的模型,那很快,我们就能够在手机、手表、电脑上运行一个好的推理模型。刚刚发现,ollama 已经集成了QWQ-32B,现在我们通过 ollama pull qwq 命令可以直接部署。
一个多月前,DeepSeek 以低廉的成本和开放的姿态,在有限的硬件条件下告诉全世界,推理模型仍能保持很好的性能表现。DeepSeek R1 的逻辑主要是通过整合冷启动数据和多阶段训练。而现在,QWQ 证明RL有潜力超越传统的预训练和后训练方法来提升模型性能。QWQ-32B,必将成为新的推理模型的游戏规则改变者。本地部署强大推理模型的能力来了。





