Meta新成立的超级智能实验室(Meta Superintelligence Labs,MSL)扔出第一篇论文,直接把检索增强生成(RAG)应用的推理速度干到了30倍以上。这篇论文叫《REFRAG:Rethinking RAG based Decoding》,让大语言模型在做RAG任务时,学会了抓重点,提炼摘要,大大减少计算量和反应时间,而且准确率不变。
Meta的超级智能实验室
6月30日,Meta超级智能实验室正式成立,总部设在加利福尼亚州的门洛帕克。实验室的目标非常明确,就是搞超级智能。新实验室成立,其实是扎克伯格真的急了。时间往前倒两个月,也就是4月,Meta发布了自家的Llama 4模型。据彭博社报道,扎克伯格对这个模型的表现相当不满意,甚至要求员工为此加班加点。
扎克伯格不高兴,后果很严重。扎克伯格意识到,他必须亲自下场抓AI了。他创建了一个WhatsApp群聊,拉上公司高管,开始满世界挖人。为了招人,扎克伯格可以说是下了血本。他看上了Scale AI这家公司,不仅砸几十亿美元投资,还把它的创始人和首席执行官Alexandr Wang直接挖过来。据《纽约时报》爆料,扎克伯格还给OpenAI和Google的员工开出了上亿美元的薪酬包挖他们。然后,扎克伯格正式宣布成立Meta超级智能实验室,Alexandr Wang出任首席AI官。
Meta AI(前身为基础人工智能研究,FAIR)和其他几个部门,包括一个新成立的叫TBD Lab的团队,全部被划归到这个新的超级智能实验室旗下。8月份,实验室内部又进行了一次重组,分成了四个小组:
TBD Lab:由Wang亲自带队,负责管Meta所有的大语言模型。
FAIR:继续做它的人工智能研究老本行。
Products and Applied Research:由Friedman领导,负责把AI技术落地到消费者产品里。
MSL Infra:由Aparna Ramani负责,专门搞基础设施,确保模型能稳定运行。
Meta超级智能实验室从诞生之日起,就承载了扎克伯格和Meta在AI领域的野心和希望。REFRAG,就是这个明星团队交出的第一份答卷。
REFRAG的聪明之处
大语言模型能通过RAG,利用外部知识库来回答问题,这在多轮对话或者智能体应用里特别有用。但你给模型喂的参考资料(也就是上下文)越长,它的反应就越慢,对内存的消耗也越大。这就导致了一个两难的局面:想要知识丰富,就得牺牲效率;想要效率高,就得减少参考资料,但影响回答质量。Meta的研究人员发现,这种低相似度的上下文,在模型的注意力机制里会形成一种特殊的“块对角”模式。就是模型在处理这些上下文时,大部分计算力都花在了分析一些互不相关的文本块上。
基于这个观察,他们想,能不能在解码生成答案的过程中,把这些不必要的计算给砍掉呢?REFRAG框架应运而生。
它的核心思想非常直接:别再把检索来的段落原文一股脑儿地喂给解码器了,而是先用一个轻量级模型把这些段落压缩成一个个“摘要”,也就是“块嵌入”(block embedding),然后再把这些浓缩后的摘要喂给解码器。
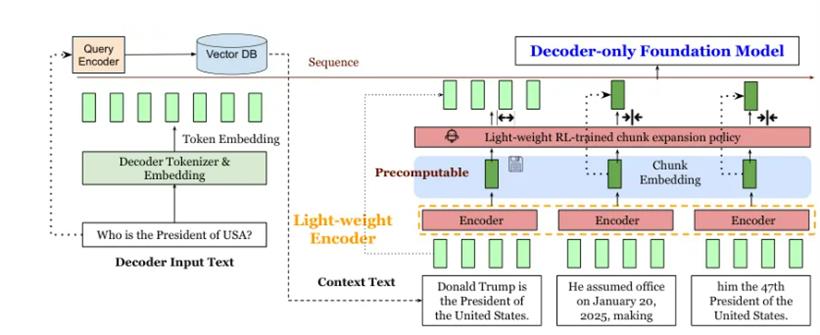
当用户输入一个问题和一堆上下文时,REFRAG会先把长长的上下文切成一个个小块。然后,一个轻量级的编码器模型(比如Roberta)会出马,为每个小块生成一个紧凑的嵌入表示,就像是给每一段内容写了个摘要。这些摘要(块嵌入)随后被转换成解码器模型(比如LLaMA)能理解的格式,和问题的嵌入表示一起,被送进解码器,最终生成答案。
因为在RAG里,上下文通常比问题本身长得多,所以用摘要代替原文,解码器的输入序列长度一下子就缩短了好几倍。输入短了,计算量自然就下来了,延迟和内存占用也就跟着降下来了。
这种做法有三大好处:
1.解码器的输入变短了,处理速度自然就快了。
2.这些“摘要”(块嵌入)在检索阶段就可以提前算好,避免了重复计算。
3.注意力机制的计算复杂度,从跟总字数的平方成正比,变成了跟“摘要”数量的平方成正比,这是一个巨大的优化。
更妙的是,REFRAG支持在任意位置压缩文本块,并且保持了解码器的自回归特性。它不仅能处理单个问题,还能很好地支持需要来回对话的多轮应用和智能体应用。为了让模型更智能,REFRAG还引入了一个强化学习策略。这个策略会动态地判断,什么时候需要看原文细节,什么时候看个摘要就足够了,从而在效率和精度之间找到最佳平衡点。那么,怎么训练模型学会这套操作呢?
研究人员用了一种叫“持续预训练”(Continual Pre-training,CPT)的方法。他们设计了一个“重建任务”:让编码器读取一段原文并生成摘要,然后要求解码器只看摘要,把原文给重建出来。这个任务的目标,就是逼着编码器学会如何在信息损失最小的情况下压缩文本,同时让解码器学会如何从摘要中解压缩出原始信息。
这个任务听起来简单,做起来很难。因为文本块的组合是指数级增长的,想用一个固定长度的嵌入来完美表示所有可能性,挑战巨大。为了解决这个难题,他们用上了“课程学习”的方法。就像教小孩子一样,先从简单的开始。一开始,只让模型学习重建一个文本块。学会了,再增加到两个,然后三个,循序渐进。通过逐步增加难度,模型就能平稳地掌握这项复杂技能。经过这一系列精心设计,REFRAG最终成型。它不需要修改大模型的底层架构,也不需要增加新的解码器参数,就能实现高效解码。
REFRAG的性能表现
研究人员在RAG、多轮对话和长文档摘要等多种任务上,对REFRAG进行了全面的测试。他们使用的基础模型是LLaMA-2-7B,训练数据来自一个叫Slimpajama的开源数据集,主要用了里面的书籍和学术论文部分,因为这些文本比较长。性能比较的结果非常惊人。
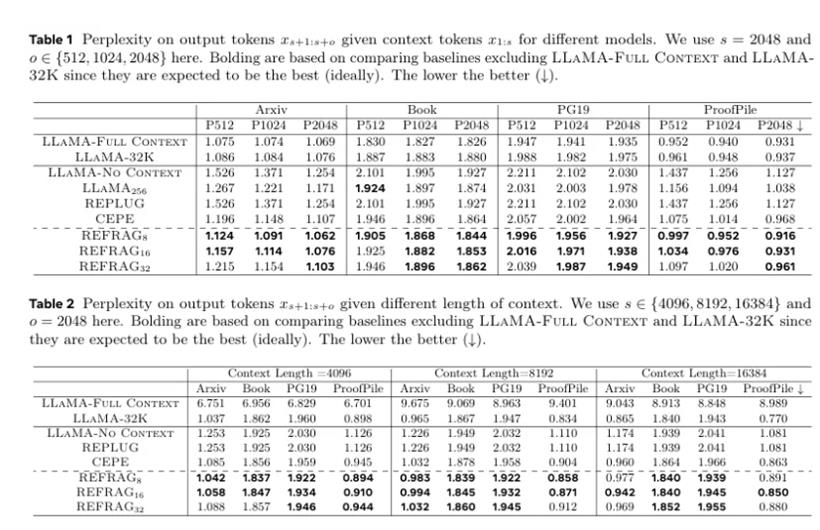
REFRAG在压缩率为8倍(REFRAG8)和16倍(REFRAG16)的情况下,几乎在所有设置中都稳定地超过了其他基线模型,包括之前最先进的CEPE模型,而且延迟更低。而且,REFRAG在Time-to-First-Token(TTFT)这个关键延迟指标上,实现了高达30.85倍的加速,是CEPE的3.75倍。同时,它还能把模型的有效上下文窗口扩展16倍,吞吐量提升了6.78倍。
所有这些性能的巨大提升,都没有以牺牲模型准确性为代价,困惑度(衡量模型性能的指标,越低越好)基本没有损失。
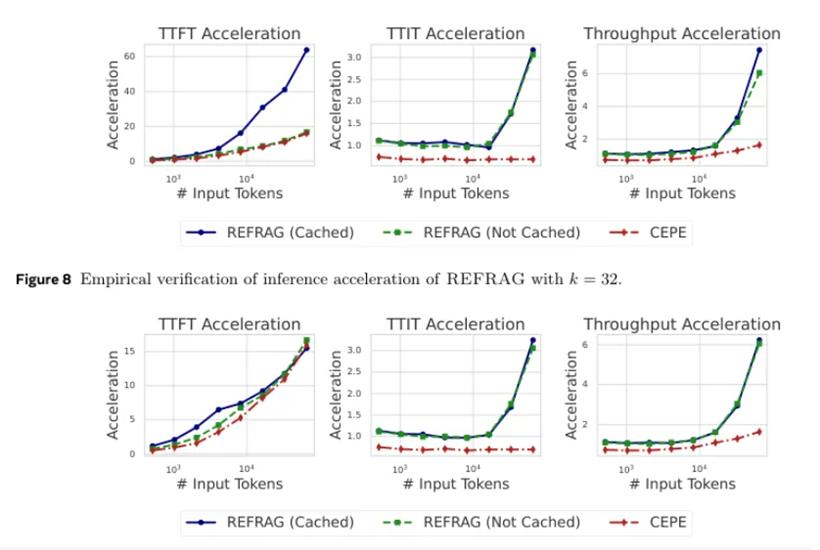
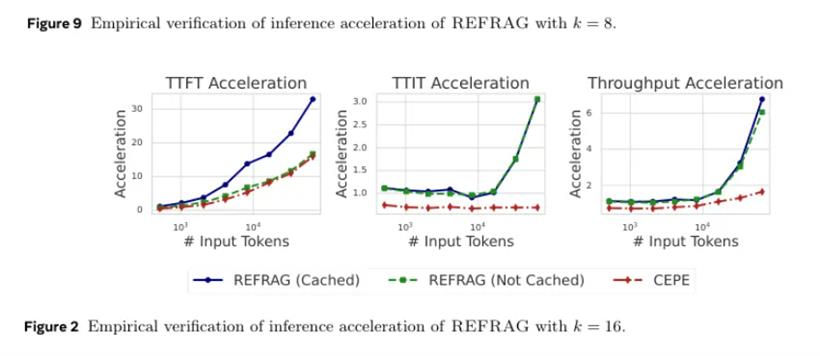
这张加速效果图显示,在16384这样中长长度的上下文里,REFRAG(k=16)的TTFT加速达到了16.53倍,吞吐量加速达到了6.78倍,都远远超过了CEPE。当压缩率提高到32倍时,TTFT加速甚至达到了惊人的32.99倍,同时性能还能和CEPE打个平手。研究人员还测试了它在真实RAG应用中的表现。
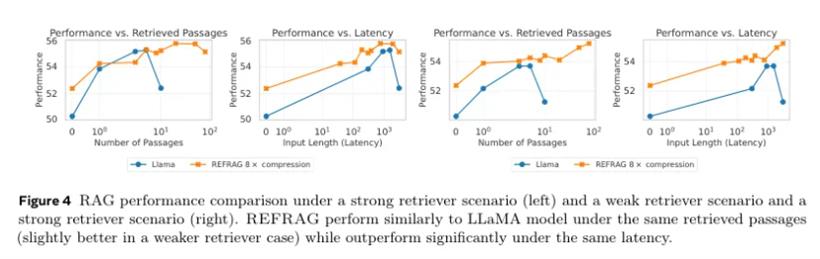
他们设计了两种场景:一种是“强检索器”,也就是检索到的文档质量很高,跟问题很相关;另一种是“弱检索器”,模拟真实世界中检索系统可能出错,找来一堆不太相关的文档。在强检索器场景下,REFRAG用同样的文档数量,性能和原始的LLaMA打平,但速度快了5.26倍。如果把省下来的时间用来多读几篇文档(比如REFRAG读8篇,LLaMA读1篇),在延迟相同的情况下,REFRAG的平均准确率还能提升1.22%。
在弱检索器这个更接近现实的场景下,REFRAG的优势更明显。因为它能用更快的速度处理更多的上下文,所以有更大的机会从一堆不太相关的文档里沙里淘金,找到有用的信息。在延迟相同的情况下,它的准确率平均提升了1.93%。在多轮对话这种需要记住前面聊了什么的场景里,REFRAG同样表现出色。
传统的LLaMA模型因为有4000个token的上下文窗口限制,聊得久了就得把前面的对话历史给截断,容易“失忆”。而REFRAG通过压缩技术,即使在很长的对话历史和大量的检索文档下,也能保持稳健的性能,不会丢失关键信息。Meta超级智能实验室的第一份作品,是非常有含金量的。它为那些对延迟敏感、知识密集的应用场景部署大语言模型,提供了一个非常实用和可扩展的解决方案。
参考资料:
https://arxiv.org/abs/2509.01092
https://en.wikipedia.org/wiki/Meta_Superintelligence_Labs
https://arxiv.org/abs/2005.11401
https://www.marktechpost.com/2025/09/07/meta-superintelligence-labs-introduces-refrag-scaling-rag-with-16x-longer-contexts-and-31x-faster-decoding


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






