- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

1.使用哈希表:可以将数据进行哈希操作,将数据存储在相应的桶中。查询时,根据哈希值定位到对应的桶,然后在桶内进行查找。这种方法的时间复杂度为 O(1),但需要额外的存储空间来存储哈希表。如果桶中存在数据,则说明此值已存在,否则说明未存在。
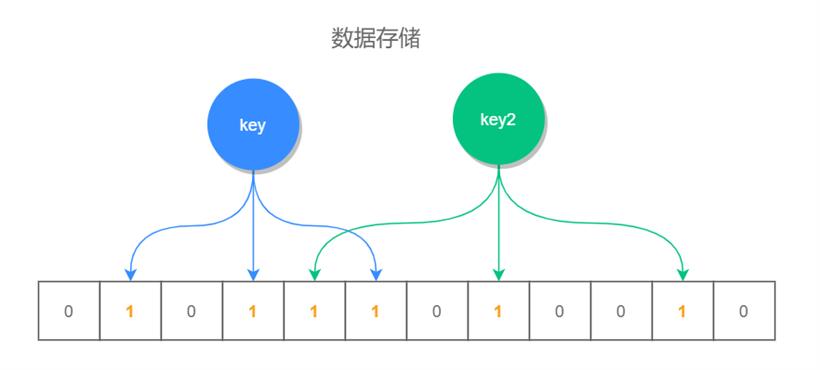
2.使用布隆过滤器:布隆过滤器是一种概率型数据结构,用于判断一个元素是否在集合中。它利用多个哈希函数映射数据到一个位数组,并将对应位置置为 1。查询时,只需要对待查询的数据进行哈希,并判断对应的位是否都为 1。如果都为 1,则该数据可能存在;如果有一个位不为 1,则该数据一定不存在。布隆过滤器的查询时间复杂度为 O(k),其中 k 为哈希函数的个数。
3.内存占用:哈希表需要根据数据规模来动态调整数组的大小,以保证存储效率。而布隆过滤器在预先设置位数组的大小后,不会随数据规模的增加而增长。因此布隆过滤器更适用于海量数据。
2.通过中间件实现(支持数据持久化):使用 Redis 4.0 之后提供的布隆过滤插件来实现,它的好处是支持持久化,数据不会丢失。
2.使用 Guava API 操作布隆过滤器
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</dependency>
② 使用 Guava APIimport com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterExample {
public static void main(String[] args) {
// 创建一个布隆过滤器,设置期望插入的数据量为10000,期望的误判率为0.01
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.unencodedCharsFunnel(), 10000, 0.01);
// 堆代码 duidaima.com
// 向布隆过滤器中插入数据
bloomFilter.put("data1");
bloomFilter.put("data2");
bloomFilter.put("data3");
// 查询元素是否存在于布隆过滤器中
System.out.println(bloomFilter.mightContain("data1")); // true
System.out.println(bloomFilter.mightContain("data4")); // false
}
}
在上述示例中,我们通过 BloomFilter.create() 方法创建一个布隆过滤器,指定了元素序列化方式、期望插入的数据量和期望的误判率。然后,我们可以使用 put() 方法向布隆过滤器中插入数据,使用 mightContain() 方法来判断元素是否存在于布隆过滤器中。