- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

2.我们应该显示地给我们的线程池命名,这样有助于我们定位问题。
/**
* 打印线程池的状态
* 堆代码 duidaima.com
* @param threadPool 线程池对象
*/
public static void printThreadPoolStatus(ThreadPoolExecutor threadPool) {
ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(1, createThreadFactory("print-images/thread-pool-status", false));
scheduledExecutorService.scheduleAtFixedRate(() -> {
log.info("=========================");
log.info("ThreadPool Size: [{}]", threadPool.getPoolSize());
log.info("Active Threads: {}", threadPool.getActiveCount());
log.info("Number of Tasks : {}", threadPool.getCompletedTaskCount());
log.info("Number of Tasks in Queue: {}", threadPool.getQueue().size());
log.info("=========================");
}, 0, 1, TimeUnit.SECONDS);
}
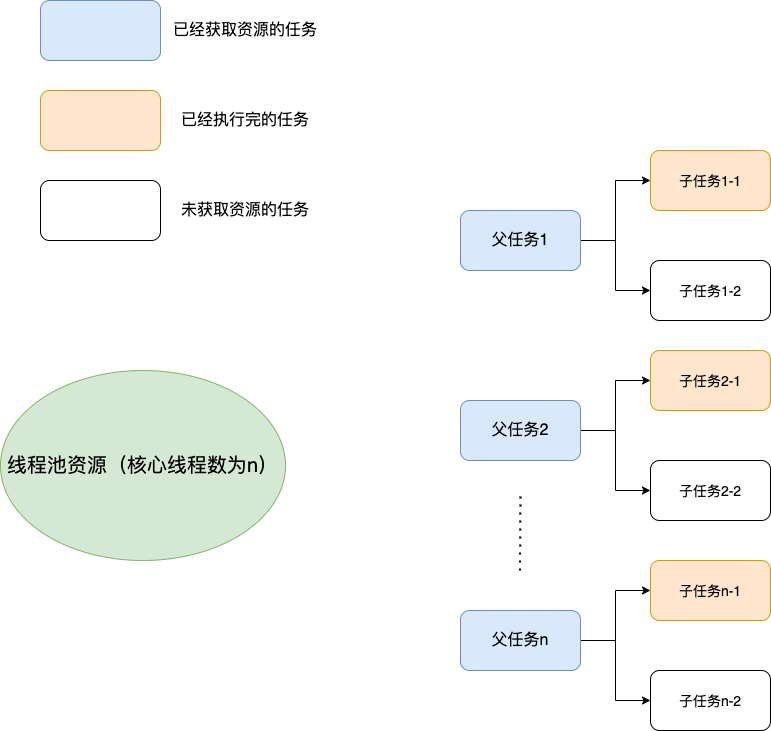
三、建议不同类别的业务用不同的线程池
ThreadFactory threadFactory = new ThreadFactoryBuilder()
.setNameFormat(threadNamePrefix + "-%d")
.setDaemon(true).build();
ExecutorService threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.MINUTES, workQueue, threadFactory)
2、自己实现 ThreadFactorimport java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 线程工厂,它设置线程名称,有利于我们定位问题。
*/
public final class NamingThreadFactory implements ThreadFactory {
private final AtomicInteger threadNum = new AtomicInteger();
private final ThreadFactory delegate;
private final String name;
/**
* 创建一个带名字的线程池生产工厂
*/
public NamingThreadFactory(ThreadFactory delegate, String name) {
this.delegate = delegate;
this.name = name; // TODO consider uniquifying this
}
@Override
public Thread newThread(Runnable r) {
Thread t = delegate.newThread(r);
t.setName(name + " [#" + threadNum.incrementAndGet() + "]");
return t;
}
}
五、正确配置线程池参数上下文切换:多线程编程中一般线程的个数都大于 CPU 核心的个数,而一个 CPU 核心在任意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU 采取的策略是为每个线程分配时间片并轮转的形式。当一个线程的时间片用完的时候就会重新处于就绪状态让给其他线程使用,这个过程就属于一次上下文切换。
概括来说就是:当前任务在执行完 CPU 时间片切换到另一个任务之前会先保存自己的状态,以便下次再切换回这个任务时,可以再加载这个任务的状态。任务从保存到再加载的过程就是一次上下文切换 。上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。
所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
如果我们设置线程数量太大,大量线程可能会同时在争取 CPU 资源,这样会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。
I/O 密集型任务(2N): 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
🌈 拓展一下:线程数更严谨的计算的方法应该是:最佳线程数 = N(CPU 核心数)∗(1+WT(线程等待时间)/ST(线程计算时间)),其中 WT(线程等待时间)=线程运行总时间 - ST(线程计算时间)。线程等待时间所占比例越高,需要越多线程。线程计算时间所占比例越高,需要越少线程。我们可以通过 JDK 自带的工具 VisualVM 来查看 WT/ST 比例。CPU 密集型任务的 WT/ST 接近或者等于 0,因此, 线程数可以设置为 N(CPU 核心数)∗(1+0)= N,和我们上面说的 N(CPU 核心数)+1 差不多。IO 密集型任务下,几乎全是线程等待时间,从理论上来说,你就可以将线程数设置为 2N(按道理来说,WT/ST 的结果应该比较大,这里选择 2N 的原因应该是为了避免创建过多线程吧)。
workQueue: 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。

Dynamic TP[5] :轻量级动态线程池,内置监控告警功能,集成三方中间件线程池管理,基于主流配置中心(已支持 Nacos、Apollo,Zookeeper、Consul、Etcd,可通过 SPI 自定义实现)。
@GetMapping("wrong")
public String wrong() throws InterruptedException {
// 自定义线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(5,10,1L,TimeUnit.SECONDS,new ArrayBlockingQueue<>(100),new ThreadPoolExecutor.CallerRunsPolicy());
// 处理任务
executor.execute(() -> {
// ......
}
return "OK";
}
出现这种问题的原因还是对于线程池认识不够,需要加强线程池的基础知识。@Configuration
@EnableAsync
public class ThreadPoolExecutorConfig {
@Bean(name="threadPoolExecutor")
public Executor threadPoolExecutor(){
ThreadPoolTaskExecutor threadPoolExecutor = new ThreadPoolTaskExecutor();
int processNum = Runtime.getRuntime().availableProcessors(); // 返回可用处理器的Java虚拟机的数量
int corePoolSize = (int) (processNum / (1 - 0.2));
int maxPoolSize = (int) (processNum / (1 - 0.5));
threadPoolExecutor.setCorePoolSize(corePoolSize); // 核心池大小
threadPoolExecutor.setMaxPoolSize(maxPoolSize); // 最大线程数
threadPoolExecutor.setQueueCapacity(maxPoolSize * 1000); // 队列程度
threadPoolExecutor.setThreadPriority(Thread.MAX_PRIORITY);
threadPoolExecutor.setDaemon(false);
threadPoolExecutor.setKeepAliveSeconds(300);// 线程空闲时间
threadPoolExecutor.setThreadNamePrefix("test-Executor-"); // 线程名字前缀
return threadPoolExecutor;
}
}
线程池和 ThreadLocal 共用的坑