

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

4.如此循环直到数据全部导出到Excel完毕。
<dependency> <groupId>com.alibaba</groupId> <artifactId>easyexcel</artifactId> <version>3.0.5</version> </dependency>2.创建海量数据的sql脚本
CREATE TABLE dept( /*部门表*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ;
#创建表EMP雇员
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/
hiredate DATE NOT NULL,/*入职时间*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) NOT NULL,/*红利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/
) ;
#工资级别表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
);
#测试数据
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
delimiter $$
#创建一个函数,名字 rand_string,可以随机返回我指定的个数字符串
create function rand_string(n INT)
returns varchar(255) #该函数会返回一个字符串
begin
#定义了一个变量 chars_str, 类型 varchar(100)
#默认给 chars_str 初始值 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'
declare chars_str varchar(100) default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
# concat 函数 : 连接函数mysql函数
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
#这里我们又自定了一个函数,返回一个随机的部门号
create function rand_num( )
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
#创建一个存储过程, 可以添加雇员
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
#set autocommit =0 把autocommit设置成0
#autocommit = 0 含义: 不要自动提交
set autocommit = 0; #默认不提交sql语句
repeat
set i = i + 1;
#通过前面写的函数随机产生字符串和部门编号,然后加入到emp表
insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
#commit整体提交所有sql语句,提高效率
commit;
end $$
#添加8000000数据
call insert_emp(100001,8000000)$$
#命令结束符,再重新设置为;
delimiter ;
3.实体类@Data
@NoArgsConstructor
@AllArgsConstructor
public class Emp implements Serializable {
@ExcelProperty(value = "员工编号")
private Integer empno;
@ExcelProperty(value = "员工名称")
private String ename;
@ExcelProperty(value = "工作")
private String job;
@ExcelProperty(value = "主管编号")
private Integer mgr;
@ExcelProperty(value = "入职日期")
private Date hiredate;
@ExcelProperty(value = "薪资")
private BigDecimal sal;
@ExcelProperty(value = "奖金")
private BigDecimal comm;
@ExcelProperty(value = "所属部门")
private Integer deptno;
}
4.vo类@Data
public class EmpVo {
@ExcelProperty(value = "员工编号")
private Integer empno;
@ExcelProperty(value = "员工名称")
private String ename;
@ExcelProperty(value = "工作")
private String job;
@ExcelProperty(value = "主管编号")
private Integer mgr;
@ExcelProperty(value = "入职日期")
private Date hiredate;
@ExcelProperty(value = "薪资")
private BigDecimal sal;
@ExcelProperty(value = "奖金")
private BigDecimal comm;
@ExcelProperty(value = "所属部门")
private Integer deptno;
}
导出核心代码@Resource
private EmpService empService;
/**
* 堆代码 duidaima.com
* 分批次导出
*/
@GetMapping("/export")
public void export() throws IOException {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
empService.export();
stopWatch.stop();
System.out.println("共计耗时: " + stopWatch.getTotalTimeSeconds()+"S");
}
public class ExcelConstants {
//一个sheet装100w数据
public static final Integer PER_SHEET_ROW_COUNT = 1000000;
//每次查询20w数据,每次写入20w数据
public static final Integer PER_WRITE_ROW_COUNT = 200000;
}
@Override
public void export() throws IOException {
OutputStream outputStream =null;
try {
//记录总数:实际中需要根据查询条件进行统计即可
//LambdaQueryWrapper<Emp> lambdaQueryWrapper = new QueryWrapper<Emp>().lambda().eq(Emp::getEmpno, 1000001);
Integer totalCount = empMapper.selectCount(null);
//每一个Sheet存放100w条数据
Integer sheetDataRows = ExcelConstants.PER_SHEET_ROW_COUNT;
//每次写入的数据量20w,每页查询20W
Integer writeDataRows = ExcelConstants.PER_WRITE_ROW_COUNT;
//计算需要的Sheet数量
Integer sheetNum = totalCount % sheetDataRows == 0 ? (totalCount / sheetDataRows) : (totalCount / sheetDataRows + 1);
//计算一般情况下每一个Sheet需要写入的次数(一般情况不包含最后一个sheet,因为最后一个sheet不确定会写入多少条数据)
Integer oneSheetWriteCount = sheetDataRows / writeDataRows;
//计算最后一个sheet需要写入的次数
Integer lastSheetWriteCount = totalCount % sheetDataRows == 0 ? oneSheetWriteCount : (totalCount % sheetDataRows % writeDataRows == 0 ? (totalCount / sheetDataRows / writeDataRows) : (totalCount / sheetDataRows / writeDataRows + 1));
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletResponse response = requestAttributes.getResponse();
outputStream = response.getOutputStream();
//必须放到循环外,否则会刷新流
ExcelWriter excelWriter = EasyExcel.write(outputStream).build();
//开始分批查询分次写入
for (int i = 0; i < sheetNum; i++) {
//创建Sheet
WriteSheet sheet = new WriteSheet();
sheet.setSheetName("测试Sheet1"+i);
sheet.setSheetNo(i);
//循环写入次数: j的自增条件是当不是最后一个Sheet的时候写入次数为正常的每个Sheet写入的次数,如果是最后一个就需要使用计算的次数lastSheetWriteCount
for (int j = 0; j < (i != sheetNum - 1 ? oneSheetWriteCount : lastSheetWriteCount); j++) {
//分页查询一次20w
Page<Emp> page = empMapper.selectPage(new Page(j + 1 + oneSheetWriteCount * i, writeDataRows), null);
List<Emp> empList = page.getRecords();
List<EmpVo> empVoList = new ArrayList<>();
for (Emp emp : empList) {
EmpVo empVo = new EmpVo();
BeanUtils.copyProperties(emp, empVo);
empVoList.add(empVo);
}
WriteSheet writeSheet = EasyExcel.writerSheet(i, "员工信息" + (i + 1)).head(EmpVo.class)
.registerWriteHandler(new LongestMatchColumnWidthStyleStrategy()).build();
//写数据
excelWriter.write(empVoList, writeSheet);
}
}
// 下载EXCEL
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
response.setCharacterEncoding("utf-8");
// 这里URLEncoder.encode可以防止浏览器端导出excel文件名中文乱码 当然和easyexcel没有关系
String fileName = URLEncoder.encode("员工信息", "UTF-8").replaceAll("\\+", "%20");
response.setHeader("Content-disposition", "attachment;filename*=utf-8''" + fileName + ".xlsx");
excelWriter.finish();
outputStream.flush();
} catch (IOException e) {
e.printStackTrace();
} catch (BeansException e) {
e.printStackTrace();
}finally {
if (outputStream != null) {
outputStream.close();
}
}
}
导出500w数据共计耗时,可以看到差不多400s左右。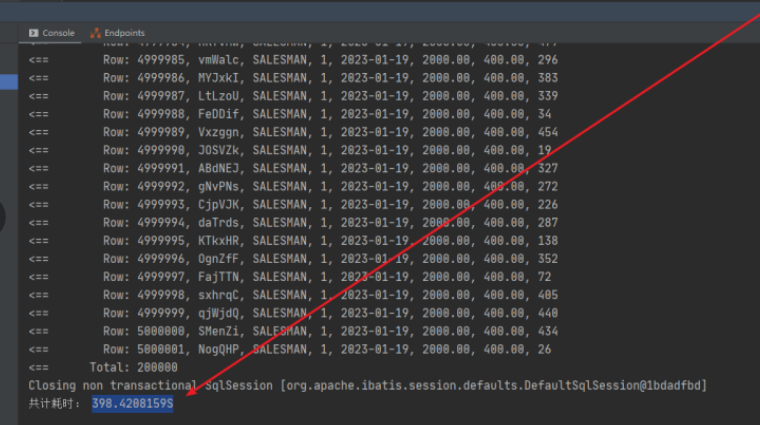
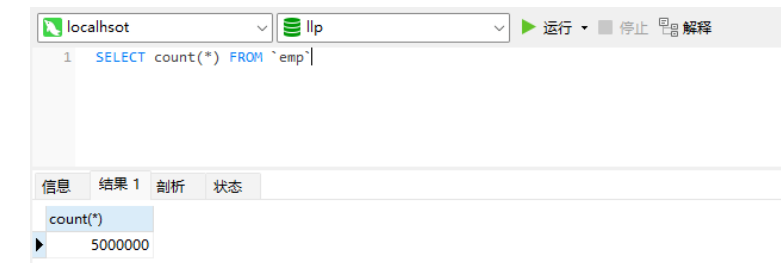
@Resource
private EmpService empService;
@GetMapping("/importData")
public void importData() {
String fileName = "C:\\Users\\asus\\Desktop\\员工信息.xlsx";
//记录开始读取Excel时间,也是导入程序开始时间
long startReadTime = System.currentTimeMillis();
System.out.println("------开始读取Excel的Sheet时间(包括导入数据过程):" + startReadTime + "ms------");
//读取所有Sheet的数据.每次读完一个Sheet就会调用这个方法
EasyExcel.read(fileName, new EasyExceGeneralDatalListener(empService)).doReadAll();
long endReadTime = System.currentTimeMillis();
System.out.println("------结束读取Excel的Sheet时间(包括导入数据过程):" + endReadTime + "ms------");
System.out.println("------读取Excel的Sheet时间(包括导入数据)共计耗时:" + (endReadTime-startReadTime) + "ms------");
}
Excel导入事件监听// 事件监听
public class EasyExceGeneralDatalListener extends AnalysisEventListener<Map<Integer, String>> {
/**
* 处理业务逻辑的Service,也可以是Mapper
*/
private EmpService empService;
/**
* 用于存储读取的数据
*/
private List<Map<Integer, String>> dataList = new ArrayList<Map<Integer, String>>();
public EasyExceGeneralDatalListener() {
}
public EasyExceGeneralDatalListener(EmpService empService) {
this.empService = empService;
}
@Override
public void invoke(Map<Integer, String> data, AnalysisContext context) {
//数据add进入集合
dataList.add(data);
//size是否为100000条:这里其实就是分批.当数据等于10w的时候执行一次插入
if (dataList.size() >= ExcelConstants.GENERAL_ONCE_SAVE_TO_DB_ROWS) {
//存入数据库:数据小于1w条使用Mybatis的批量插入即可;
saveData();
//清理集合便于GC回收
dataList.clear();
}
}
/**
* 保存数据到DB
*
* @param
* @MethodName: saveData
* @return: void
*/
private void saveData() {
empService.importData(dataList);
dataList.clear();
}
/**
* Excel中所有数据解析完毕会调用此方法
*
* @param: context
* @MethodName: doAfterAllAnalysed
* @return: void
*/
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
saveData();
dataList.clear();
}
}
核心业务代码public interface EmpService {
void export() throws IOException;
void importData(List<Map<Integer, String>> dataList);
}
/*
* 测试用Excel导入超过10w条数据,经过测试发现,使用Mybatis的批量插入速度非常慢,所以这里可以使用 数据分批+JDBC分批插入+事务来继续插入速度会非常快
*/
@Override
public void importData(List<Map<Integer, String>> dataList) {
//结果集中数据为0时,结束方法.进行下一次调用
if (dataList.size() == 0) {
return;
}
//JDBC分批插入+事务操作完成对20w数据的插入
Connection conn = null;
PreparedStatement ps = null;
try {
long startTime = System.currentTimeMillis();
System.out.println(dataList.size() + "条,开始导入到数据库时间:" + startTime + "ms");
conn = JDBCDruidUtils.getConnection();
//控制事务:默认不提交
conn.setAutoCommit(false);
String sql = "insert into emp (`empno`, `ename`, `job`, `mgr`, `hiredate`, `sal`, `comm`, `deptno`) values";
sql += "(?,?,?,?,?,?,?,?)";
ps = conn.prepareStatement(sql);
//循环结果集:这里循环不支持lambda表达式
for (int i = 0; i < dataList.size(); i++) {
Map<Integer, String> item = dataList.get(i);
ps.setString(1, item.get(0));
ps.setString(2, item.get(1));
ps.setString(3, item.get(2));
ps.setString(4, item.get(3));
ps.setString(5, item.get(4));
ps.setString(6, item.get(5));
ps.setString(7, item.get(6));
ps.setString(8, item.get(7));
//将一组参数添加到此 PreparedStatement 对象的批处理命令中。
ps.addBatch();
}
//执行批处理
ps.executeBatch();
//手动提交事务
conn.commit();
long endTime = System.currentTimeMillis();
System.out.println(dataList.size() + "条,结束导入到数据库时间:" + endTime + "ms");
System.out.println(dataList.size() + "条,导入用时:" + (endTime - startTime) + "ms");
} catch (Exception e) {
e.printStackTrace();
} finally {
//关连接
JDBCDruidUtils.close(conn, ps);
}
}
}
jdbc工具类//JDBC工具类
public class JDBCDruidUtils {
private static DataSource dataSource;
/*
创建数据Properties集合对象加载加载配置文件
*/
static {
Properties pro = new Properties();
//加载数据库连接池对象
try {
//获取数据库连接池对象
pro.load(JDBCDruidUtils.class.getClassLoader().getResourceAsStream("druid.properties"));
dataSource = DruidDataSourceFactory.createDataSource(pro);
} catch (Exception e) {
e.printStackTrace();
}
}
/*
获取连接
*/
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
/**
* 关闭conn,和 statement独对象资源
*
* @param connection
* @param statement
* @MethodName: close
* @return: void
*/
public static void close(Connection connection, Statement statement) {
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 关闭 conn , statement 和resultset三个对象资源
*
* @param connection
* @param statement
* @param resultSet
* @MethodName: close
* @return: void
*/
public static void close(Connection connection, Statement statement, ResultSet resultSet) {
close(connection, statement);
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/*
获取连接池对象
*/
public static DataSource getDataSource() {
return dataSource;
}
}
druid.properties配置文件# druid.properties配置 driverClassName=com.mysql.jdbc.Driver url=jdbc:mysql://localhost:3306/llp?autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=GMT%2B8&allowMultiQueries=true&rewriteBatchedStatements=true username=root password=root initialSize=10 maxActive=50 maxWait=60000测试结果
------开始读取Excel的Sheet时间(包括导入数据过程):1674181403555ms------
200000条,开始导入到数据库时间:1674181409740ms
2023-01-20 10:23:29.943 INFO 18580 --- [nio-8888-exec-1] com.alibaba.druid.pool.DruidDataSource : {dataSource-1} inited
200000条,结束导入到数据库时间:1674181413252ms
200000条,导入用时:3512ms
200000条,开始导入到数据库时间:1674181418422ms
200000条,结束导入到数据库时间:1674181420999ms
200000条,导入用时:2577ms
.....
200000条,开始导入到数据库时间:1674181607405ms
200000条,结束导入到数据库时间:1674181610154ms
200000条,导入用时:2749ms
------结束读取Excel的Sheet时间(包括导入数据过程):1674181610155ms------
------读取Excel的Sheet时间(包括导入数据)共计耗时:206600ms------
从打印结果可以看出,在我的电脑上导入500w数据差不多需要200多秒的时间。


