- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

我们有一个项目,采用了全内存缓存机制。一方面是为了追求卓越的RT,另一方面是数据量确实很小,标准的4C8G容器处理起来绰绰有余。可是突然有一天,预发环境,疯狂报警FullGC,定位了一下原因,原来是这个缓存变得太大了。
我们通常会把数据量级在百条左右的配置项加载到内存里,近期一个新需求,导致配置数据量膨胀到了十万级,一口气加载到了内存里,自然造成了内存占用的上涨。但是,经过分析,这些数据的信息熵并不是很高。大面积的json其实是在存储有限种排列组合的字符串,但是这些字符串被反序列化框架以 new String 的方式重复加载到了堆空间内。
突然想到了常量池这个概念,打算把它用起来,这样在不改变本次设计的情况下,可以无业务入侵地解决这个问题。首先明确,我们使用的fastjson序列化工具,是不会对“value”做常量池处理的。这也很好理解,因为正常情况下,value代表着无限可能,把每一个扑面而来的字符串都放到常量池内,显然会对系统带来更糟糕的影响。不过,我们很清楚自己的业务场景,特定value是有限的,不需要被Young GC的,因此,我们需要把这些特定的“value”,常量化,即显式调用 String.intern() 方法。
说干就干,我们找到可以用来写 String.intern() 的“切点”。
public class StringPoolDeserializer implements ObjectDeserializer {
@SuppressWarnings("unchecked")
@Override
public <T> T deserialze(DefaultJSONParser parser, Type type, Object o) {
if (!type.equals(String.class)) {
throw new JSONException("StringPoolDeserializer can only deserialize String");
}
// 堆代码 duidaima.com
return (T) ((String) parser.parse(o)).intern();
}
@Override
public int getFastMatchToken() {
return 0;
}
}
经此优化,已经干掉了800M堆内存,并且元空间几乎没有上涨,毕竟我们的数据信息熵很低,都是重复的。 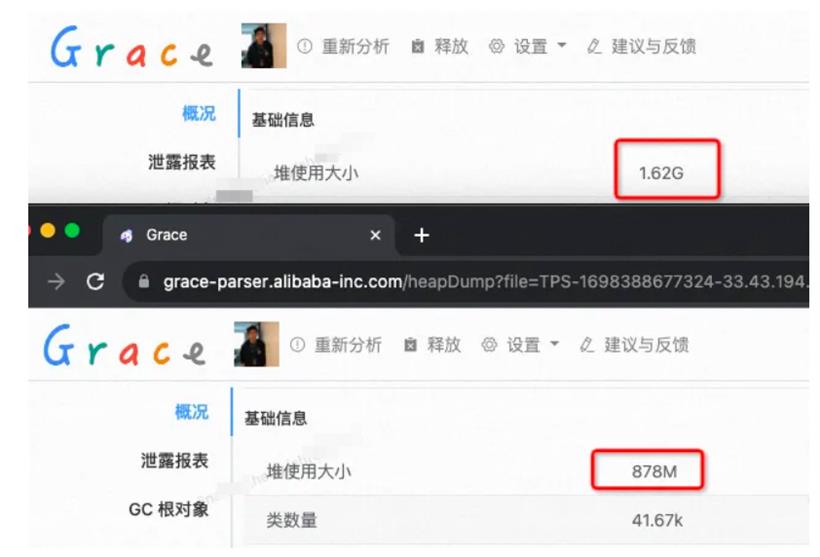
不过,剩余大小还是大于预期,后来发现,这个做法无法处理Map<String, String>类型的成员里面的value。
进一步,再看一下Map是如何被处理的。fastjson内部实现了 MapDeserializer 用来反序列化类型为Map的字段。不过这个反序列化器实现比较复杂,核心机制所在方法都被final修饰,不适合使用继承重写替换的方式解决问题。后来,发现代码里存在一条唯一的value。map的通路,我们可以通过干预map的类型,*重写对应的put方法,从而找到合适的 String.intern() 调用点。
*p.s. 除put方法外,Map的 putAll, “compute家族”,甚至有参构造方法等,也有向Map添加元素的能力,他们并不复用put方法,而是复用一个被final关键字修饰的方法 ( putVal )。严格来说,由于无法重写 putVal方法,这些方法也应该被相应地重写,但考虑到 MapDeserializer 只调用了put方法,其余方法实现更复杂,故此只重写了put方法。
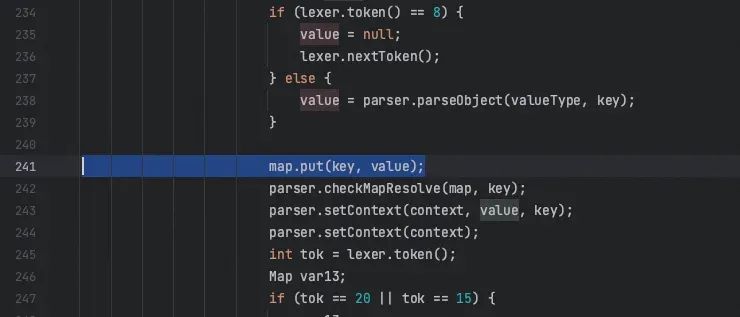
public class StringPoolMap extends HashMap<String, String> {
@Override
public String put(String key, String value) {
if (key != null) {
key = key.intern();
}
if (value != null) {
value = value.intern();
}
return super.put(key, value);
}
}
至此,能通过trick优化的地方已经全被优化掉了,内存占用从800M干到了619M,相较最初的1.6G+,成功干掉了1G的空间。
本次优化,就当是把“八股”简单地在生产环境中实战一下,顺便读了读fastjson的源码,收获良多。
#include "jvm.h"
#include "java_lang_String.h"
JNIEXPORT jobject JNICALL
Java_java_lang_String_intern(JNIEnv *env, jobject this)
{
return JVM_InternString(env, this);
}
里面实际上调用了一个 JVM_InternString,把this这个Object传了进去。#include "jvm.h"
#include "java_lang_String.h"
JNIEXPORT jobject JNICALL
Java_java_lang_String_intern(JNIEnv *env, jobject this)
{
return JVM_InternString(env, this);
}
StringTableoop StringTable::intern(Handle string_or_null_h, const jchar* name, int len, TRAPS) {
unsigned int hash = java_lang_String::hash_code(name, len);
// 分别在shared table 和local table中查找有无存在的string
// 找到则快速返回
oop found_string = lookup_shared(name, len, hash);
if (found_string != nullptr) {
return found_string;
}
if (_alt_hash) {
hash = hash_string(name, len, true);
}
found_string = do_lookup(name, len, hash);
if (found_string != nullptr) {
return found_string;
}
// 没有找到的话,则创建并塞入
return do_intern(string_or_null_h, name, len, hash, THREAD);
}
(-End-)