

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

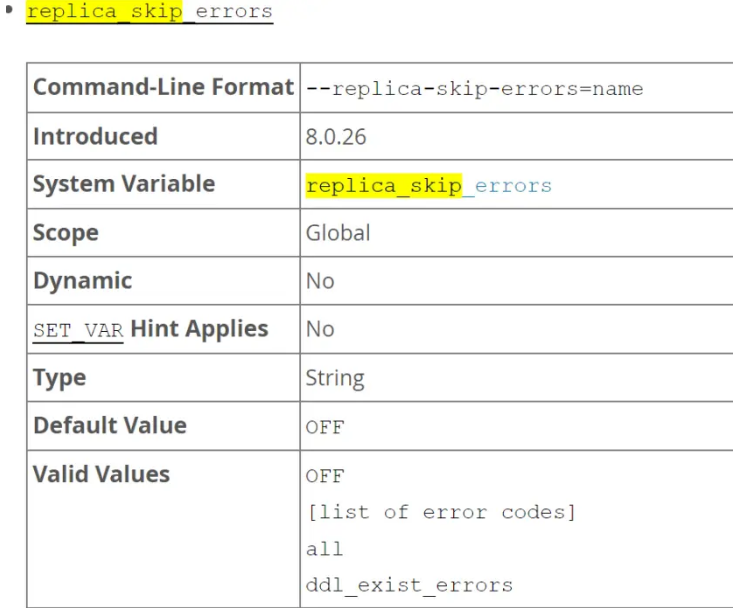
SHOW VARIABLES LIKE 'replica_skip_errors';
在你提供的示例中,replica_skip_errors的值设置为1032,10621。这意味着,如果从服务器在复制过程中遇到错误码1032或1062,它将跳过这些错误,并继续复制进程。
这些错误可能是由于在主服务器上的数据与从服务器上的数据不一致所引起的。
SET GLOBAL replica_skip_errors = '1032,1062';
此命令将全局设置replica_skip_errors变量,从而在复制过程中跳过错误码1032和1062。
了解所有可能的MySQL错误码及其含义是非常重要的,这将帮助你更好地理解和解决可能遇到的问题。你可以在MySQL的官方文档中找到所有错误码的列表和描述。





