PostgreSQL的全文本搜索(Full-Text Search,简称FTS)经常被认为比不上专用的搜索引擎或高级扩展,其性能甚至被认为是硬伤。事实并非如此,只需进行标准优化就能让内置FTS脱胎换骨,实现惊人的速度提升。本篇文章将逐步解析PostgreSQL全文本搜索的性能优化之道,助力开发者摆脱误解,挖掘强大的内置功能。
我们以为例子:
CREATE TABLE benchmark_logs (
id SERIAL PRIMARY KEY,
message TEXT,
country VARCHAR(255),
severity INTEGER,
timestamp TIMESTAMP,
metadata JSONB
);
误解:标准FTS“慢”的原因
许多人在实践中可能会在WHERE条件中动态计算tsvector,比如下面的代码:
#堆代码 duidaima.com
SELECT country, COUNT(*)
FROM benchmark_logs
WHERE to_tsvector('english', message) @@ to_tsquery('english', 'research')
GROUP BY country
ORDER BY country;
其中:
WHERE to_tsvector('english', message) @@ to_tsquery('english', 'research')
此种方式会让PostgreSQL重复执行to_tsvector()的解析和词干化操作,导致性能大打折扣。更糟的是,即使有GIN索引也不能充分发挥其效率。
优化步骤:正确姿势让FTS速度翻倍
1). 预计算tsvector并存储
最有效的优化之一是预先计算tsvector并存储在专用列中。以下是实现步骤:
1. 添加message_tsvector列:
ALTER TABLE benchmark_logs ADD COLUMN message_tsvector tsvector;
2. 使用更新语句填充列:
UPDATE benchmark_logs SET message_tsvector = to_tsvector('english', message);
3. 创建专用的GIN索引,并关闭fastupdate:
CREATE INDEX idx_gin_logs_message_tsvector
ON benchmark_logs USING GIN (message_tsvector)
WITH (fastupdate = off);
这样可以避免每次查询时动态计算tsvector,直接利用优化后的索引,显著提升查询速度。
2). 重写查询,利用预计算列
将原始查询替换为使用message_tsvector列:
SELECT country, COUNT(*)
FROM benchmark_logs
WHERE message_tsvector @@ to_tsquery('english', 'research')
GROUP BY country
ORDER BY country;
结果:性能提升50倍
通过以上优化,我们在一个包含千万条日志的测试数据集上进行查询:

• 未优化的查询:耗时约41.3秒
• 优化后的查询:耗时约0.88秒
仅需几步操作,PostgreSQL内置FTS的性能提升了约50倍。不仅解决了性能问题,还更贴合真实的生产环境需求。
超越标准FTS:高性能排序扩展
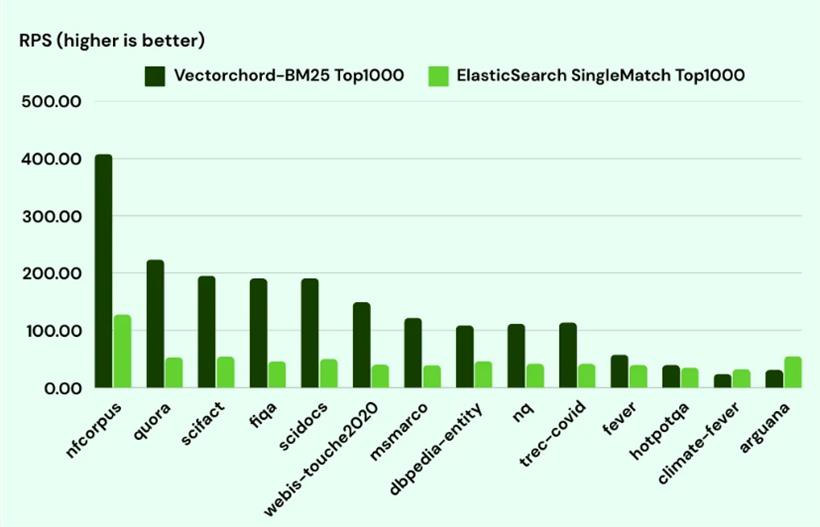
尽管标准FTS在查询性能上表现亮眼,但在排序性能方面,例如使用ts_rank函数时,可能仍然会有瓶颈。对于更加复杂的排序需求,可以考虑使用VectorChord-BM25扩展。这种扩展采用BM25算法,通过专门的索引和数据结构,极大提升排序性能,并提供更加精准的相关性评分。
 总结:内置FTS潜力无限
总结:内置FTS潜力无限
PostgreSQL的全文本搜索功能在正确优化后,可以表现出色,完全胜任大规模数据集的查询需求。如果应用场景对相关性排序有高性能要求,可以进一步探索专用扩展如VectorChord-BM25。正确选择工具,才能让你的PostgreSQL性能发挥到极致。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号





