

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号


import requests
import time
def download_site(url, session):
with session.get(url) as response:
print(f"下载了{len(response.content)}行数据")
# 堆代码 duidaima.com
def download_all_sites(sites):
with requests.Session() as session:
for url in sites:
download_site(url, session)
if __name__ == "__main__":
sites = ["https://v3u.cn"] * 50
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"下载了 {len(sites)}次,执行了{duration}秒")
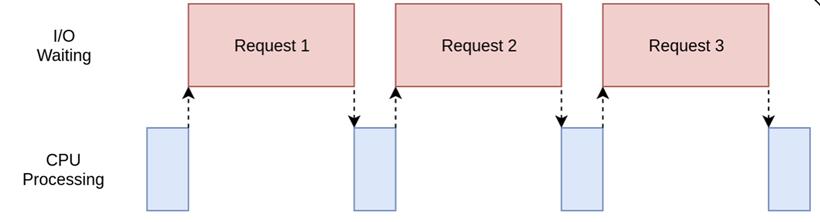
在不使用任何并发手段的前提下,程序返回:下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了76347行数据 下载了 50 次数据,执行了8.781155824661255秒 [Finished in 9.6s]这里程序的每一步都是同步操作,也就是说当第一次抓取网站首页时,剩下的49次都在等待。
import concurrent.futures
import requests
import threading
import time
thread_local = threading.local()
def get_session():
if not hasattr(thread_local, "session"):
thread_local.session = requests.Session()
return thread_local.session
def download_site(url):
session = get_session()
with session.get(url) as response:
print(f"下载了{len(response.content)}行数据")
def download_all_sites(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=8) as executor:
executor.map(download_site, sites)
if __name__ == "__main__":
sites = ["https://v3u.cn"] * 50
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"下载了 {len(sites)}次,执行了{duration}秒")
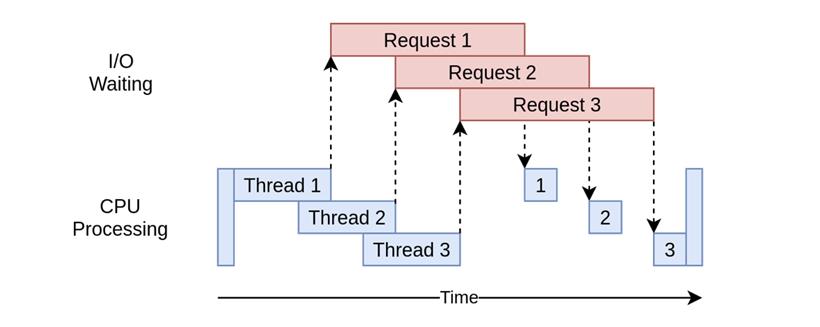
这里通过with关键词开启线程池上下文管理器,并发8个线程进行下载,程序返回:下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76161行数据 下载了76424行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据 下载了 50次,执行了7.680492877960205秒很明显,效率上有所提升,事实上,每个线程其实是在不停“切换”着运行,这就节省了单线程每次等待爬取结果的时间:
pip3 install aiohttp改写逻辑:
import asyncio
import time
import aiohttp
async def download_site(session, url):
async with session.get(url) as response:
print(f"下载了{response.content_length}行数据")
async def download_all_sites(sites):
async with aiohttp.ClientSession() as session:
tasks = []
for url in sites:
task = asyncio.ensure_future(download_site(session, url))
tasks.append(task)
await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == "__main__":
sites = ["https://v3u.cn"] * 50
start_time = time.time()
asyncio.run(download_all_sites(sites))
duration = time.time() - start_time
print(f"下载了 {len(sites)}次,执行了{duration}秒")
程序返回:下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76424行数据 下载了76161行数据 下载了76424行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据 下载了76161行数据下载了 50次,执行了6.893810987472534秒效率上百尺竿头更进一步,同样的使用with关键字操作上下文管理器,协程使用asyncio.ensure_future()创建任务列表,该列表还负责启动它们。创建所有任务后,使用asyncio.gather()来保持会话上下文的实例,直到所有爬取任务完成。和多线程threading的区别是,协程并不需要切换上下文,因此每个任务所需的资源和创建时间要少得多,因此创建和运行更多的任务效率更高:

import requests
import multiprocessing
import time
session = None
def set_global_session():
global session
if not session:
session = requests.Session()
def download_site(url):
with session.get(url) as response:
name = multiprocessing.current_process().name
print(f"读了{len(response.content)}行")
def download_all_sites(sites):
with multiprocessing.Pool(initializer=set_global_session) as pool:
pool.map(download_site, sites)
if __name__ == "__main__":
sites = ["https://v3u.cn"] * 50
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"下载了 {len(sites)}次,执行了{duration}秒")
这里我们依然使用上下文管理器开启进程池,默认进程数匹配当前计算机的CPU核心数,也就是有几核就开启几个进程,程序返回:读了76000行 读了76241行 读了76044行 读了75894行 读了76290行 读了76312行 读了76419行 读了76753行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 读了76290行 下载了 50次,执行了8.195281982421875秒虽然比同步程序要快,但无疑的,效率上要低于多线程和协程。为什么?因为多进程不适合IO密集型任务,虽然可以利用多核资源,但没有任何意义:
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
for number in numbers:
cpu_bound(number)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"{duration}秒")
同步执行20次,需要花费多少时间?4.466595888137817秒再来试试并行方式:
import multiprocessing
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
with multiprocessing.Pool() as pool:
pool.map(cpu_bound, numbers)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"{duration}秒")
八核处理器,开八个进程开始跑:1.1755797863006592秒不言而喻,并行方式有效提高了计算效率。
import concurrent.futures
import time
# 堆代码 duidaima.com
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
with concurrent.futures.ThreadPoolExecutor(max_workers=8) as executor:
executor.map(cpu_bound, numbers)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"{duration}秒")
单进程开8个线程,走起:有经验的汽修师傅会告诉你,想省油就选CVT和双离合,想质量稳定就选AT,经常高速上激烈驾驶就选双离合,经常市区内堵车就选CVT;同样地,作为经验丰富的后台研发,你也可以告诉汽修师傅,任何不需要CPU等待的任务就选择并行(multiprocessing)的处理方式,而需要CPU等待时间过长的任务,选择并发(threading/asyncio)。
反过来,我就想用CVT在高速上飙车,用双离合在市区堵车,行不行?行,但没有意义,或者说的更准确一些,没有任何额外的收益;而用并发方式执行CPU密集型任务,用并行方式执行IO密集型任务行不行?也行,但依然没有任何额外的收益, 无他,唯物无定味,适口者珍矣。





