未登录用户
首 页
书 架
登录系统
注册账号
联系我们
duidaima.com
版权声明
闽ICP备2020021581号
闽公网安备 35020302035485号
搜索
我要提问
随便写写
我要写书
论项目开发,claude 3.7 舍我其谁?
发布于 2个月前
608 热度
11 评论
一苇以航
0 粉丝 53 篇博客
关注
打赏
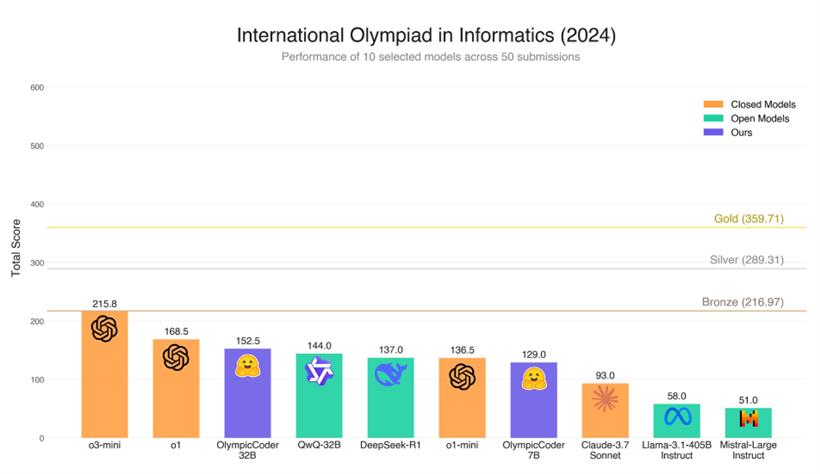
感觉一些人对 claude 3.7 sonnet 有误解,以为是编程领域最强的模型。其实只是“某种意义”上的最强。编程分两种,一种是 CURD 工程化,也就是 claude 3.7 sonnet 擅长的领域,用朴实无华的编程技能,把整个页面写完善,出成品,这是 claude 3.7 的强项。另一种编程领域,是竞赛制编程,和数学推理能力很接近,在这一点上 o3-mini-high 要明显强过 claude 3.7 ,所以 claude 3.7 编程专项领域的跑分,看起来并不算太亮眼。
下图是最新的编程竞赛跑分,3.7 连 deepseek r1 都没能打过,实在很遗憾。但是论项目开发,claude 3.7 舍我其谁!
用户评论
路生云烟
claude 3.7真有那么好用吗?
2025/3/19 7:25:00
[
0
]
[
0
]
回复
深渊骑士
一种是 CURD 工程化,也就是 claude 3.7 sonnet 擅长的领域 —— 这个不正是大多数人所需要的
2025/3/18 10:30:00
[
0
]
[
0
]
回复
回忆在沉淀
sonnet 好用是因为 cursor 写了不少内部提示词,跟工具配合最好,解决问题事半功倍,所以最好用。o3-mini 便宜但不认 cursor 的提示词,只适合开新对话处理新问题,并且你自己的提示词要写一大堆。不在 cursor 环境下,如果是直接网页上对话,最强的目前是 grok3 think 吧,几乎可以解决一切难题,思考过程比 deepseek R1 还要长。
2025/3/18 10:29:00
[
0
]
[
0
]
回复
月下独饮
claude 3.7 得看是谁家的 cluade ,大模型是一部分,还要上下文,角色调教,目前看 cursor 和 copilot 的 3.7 都不错,但是我更喜欢 copilot 的界面,cursor 的新界面给我用吐了。
2025/3/18 10:27:00
[
0
]
[
0
]
回复
一杯忘情
编程排名目前只认 https://aider.chat/docs/leaderboards/。Exercism Hard 题 + 多语言综合测试,得出来的结果可以说是最接近实际情况的,有效防止小模型刷榜。还有一点,claude 系列的 agent 能力真的特别强,这点似乎还没有哪类排行榜可以体现,但是这个对于大项目来说是必须的。
上周在一个不熟悉项目的遇到一个小 bug ,试了下直接让 AI 分析,o3-mini 和 claude 3.7 sonnet 的表现大致如下:
o3-mini:只看我给的上下文,然后思考半天作答,结果自然是完全不对。
claude 3.7 sonnet:看完我给的上下文后,顺着调用链不断阅读代码……竟然真的准确定位到了问题,问它这整个调用流程是啥样的也能答上来。
anthropic 别的不说,在编程这方面绝对是最务实的公司,很清楚在编程方面真正需要的能力是什么。
2025/3/18 10:16:00
[
0
]
[
0
]
回复
共老河山
这模型代码能力行不行,我们这些天天写前端的人还不清楚么?我用了三年 GPT-4 ,显卡烧穿了,经费花空了,现在好不容易等来 claude3.7 ,可你们非说这是人工智障!
2025/3/18 10:14:00
[
0
]
[
0
]
回复
遥忘而立
别的不说,cursor 默认 claude 就说明了很多,专门做编程领域的,肯定调研测试了很多才做的模型选择。
2025/3/18 10:11:00
[
0
]
[
0
]
回复
独白情歌
可拉到吧,claude 能理解我要什么, 谁关心跑分 甚至上边的图我都不愿意点开 其他的差太远太远 根本不值得一比
2025/3/18 10:07:00
[
0
]
[
0
]
回复
亦東風
claude 后端不行,写个三缓冲都写不明白
2025/3/18 10:05:00
[
0
]
[
0
]
回复
深山夕照
找顺手的模型就好了. 没必要必须选最好的. 未来每个公司的模型 taste 都不一样.肯定会细分的
1. 提示词对输出的提升 可能 更重要
2. 还是根据自我感觉来吧 benchmark 都是玩具 定向微调数据+蒸馏 能让 8b 跑上某个榜的前几
2025/3/18 9:18:00
[
0
]
[
0
]
回复
旧街浪人
嗯,都是牛马,谁关心竞赛制编程。所以 claude 3.7 他就是编程领域最强!
2025/3/18 9:16:00
[
0
]
[
0
]
回复
点击加载更多评论
吐槽.灌水
453 成员 |
1972 话题
+我要提问
+随便写写
可能感兴趣的话题
百度网盘真是太恶心了!我几M的下载速度硬是给我限制成100来KB
我一直很好奇 oppo\vivo 这种手机到底是谁再买?
如何看待“死了么”APP冲到 ios 付费榜第一?
30 岁生日的碎碎念


 闽公网安备 35020302035485号
闽公网安备 35020302035485号







上周在一个不熟悉项目的遇到一个小 bug ,试了下直接让 AI 分析,o3-mini 和 claude 3.7 sonnet 的表现大致如下:
o3-mini:只看我给的上下文,然后思考半天作答,结果自然是完全不对。
claude 3.7 sonnet:看完我给的上下文后,顺着调用链不断阅读代码……竟然真的准确定位到了问题,问它这整个调用流程是啥样的也能答上来。
anthropic 别的不说,在编程这方面绝对是最务实的公司,很清楚在编程方面真正需要的能力是什么。
1. 提示词对输出的提升 可能 更重要
2. 还是根据自我感觉来吧 benchmark 都是玩具 定向微调数据+蒸馏 能让 8b 跑上某个榜的前几