

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

计算资源:通常情况下,训练和微调 LLM 涉及对大数据集执行数量级更多的计算。为了加速这个过程,使用专用硬件,例如 GPU,以实现更快的数据并行操作。对于训练和部署大型语言模型而言,访问这些专用计算资源变得至关重要。推理的成本也可能使模型压缩和蒸馏技术变得重要。
迁移学习:与许多传统 ML 模型不同,许多 LLM 从基础模型开始,并使用新数据进行微调,以提高特定领域的性能。微调允许使用更少的数据和计算资源获得特定应用的最先进性能。
人类反馈:通过人类反馈的强化学习(RLHF)是训练 LLM 的主要改进之一。更通用的说法是,由于 LLM 任务通常非常开放,因此应用程序最终用户的人类反馈通常对评估 LLM 性能至关重要。将这个反馈循环集成到 LLMOps 流水线中既简化了评估,又为将来对 LLM 进行微调提供了数据。
超参数调优:在传统 ML 中,超参数调优通常集中在提高准确性或其他指标上。对于 LLM,调优也变得重要,以减少训练和推理的成本和计算能力需求。例如,调整批次大小和学习速率可以显著改变训练的速度和成本。因此,传统 ML 模型和 LLM 都会受益于跟踪和优化调优过程,但重点不同。
性能指标:传统 ML 模型具有非常清晰的性能指标,例如准确性、AUC、F1 分数等。这些指标相对简单易计算。然而,评估 LLM 时,需要应用一整套不同的标准指标和评分,例如双语评估杂志 (BLEU) 和面向摘要的召回率学生评估 (ROUGE),这在实施时需要一些额外的考虑。
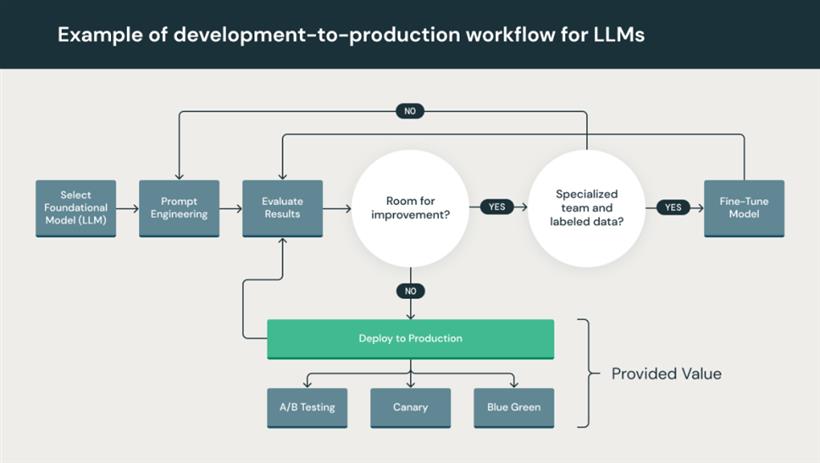
提示工程:遵循指示的模型可以接受复杂的提示或指令集。构建这些提示模板对于获得 LLM 的准确、可靠反馈至关重要。提示工程可以减少模型产生幻觉和提示黑客攻击的风险,包括提示注入、泄露敏感数据和越狱。
数据准备和提示工程:迭代地转换、聚合和去重数据,并使数据在数据团队之间可见和可分享。迭代地开发用于 LLM 的结构化、可靠查询的提示。
模型微调:使用流行的开源库,如 Hugging Face Transformers、DeepSpeed、PyTorch、TensorFlow 和 JAX 来微调和提高模型性能。
模型审查和治理:跟踪模型和流水线的溯源和版本,管理这些工件及其生命周期的过渡。使用开源 MLOps 平台,如 MLflow,在 ML 模型之间发现、分享和协作。
模型推理和服务:在测试和质量保证中,管理模型刷新的频率、推断请求次数和类似的生产细节。使用 CI/CD 工具,如代码仓库和编排器(借鉴 DevOps 原则),以自动化预生产流水线。启用带有 GPU 加速的 REST API 模型端点。
LLMOps 平台为数据科学家和软件工程师提供一个协作环境,该环境促进了迭代的数据探索、实时的共同工作能力,用于实验跟踪、提示工程、模型和流水线管理,以及受控的模型转换、部署和监控 LLM。LLMOps 自动化了机器学习生命周期的操作、同步和监控方面。






