这半年大模型可谓是杀疯了。许多朋友会下载开源的大模型在自己电脑上跑甚至做微调。
然而许多人会有这样的困惑,不清楚自己的GPU显存是否能满足当前模型的要求。毕竟,理解 GPU 能处理哪些 LLM,并不像认识模型的大小那么直观。在推理过程中(KV 缓存),模型会吃掉大片内存。比如说,一个 llama-2-7b 模型,如果序列长度为 1000,就需要额外 1GB 的内存。而且,在训练过程中,KV 缓存、激活和量化也会吞噬大量内存。
那么,我们有可能提前知道这些内存的消耗情况吗?GitHub 上出现了一个新的项目,它可以帮助你估计在训练或推理 LLM 过程中需要的 GPU 内存量。而且,这个项目还能让你了解详细的内存使用情况,评估量化方法的选择,处理的最大上下文长度等问题,从而帮助你选择适合自己的 GPU 配置。
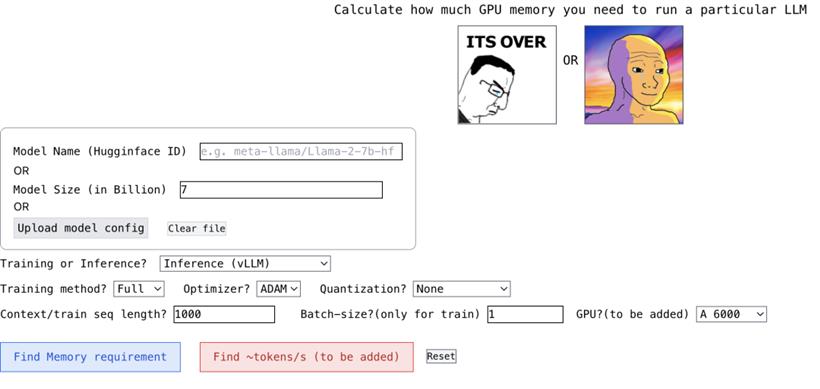
这个项目还有个特色,就是它很互动。你只要像填空题一样,输入一些必要的参数,你需要的答案就出来了。
地址放在文末了。
输出的形式大概是这样的:
{
"Total": 4000,
"KV Cache": 1000,
"Model Size": 2000,
"Activation Memory": 500,
"Grad & Optimizer memory": 0,
"cuda + other overhead": 500
}
这个项目的作者 Rahul Shiv Chand 提到,他创建这个项目的原因有:
1.你应该选择什么样的量化方法来适应在 GPU 上运行的 LLM?
2.GPU 能处理的最大上下文长度是多少?
3.什么样的微调方法最适合你?是 Full?还是 LoRA?还是 QLoRA?
4.在微调期间,你可以使用的最大 batch 是多少?
5.哪项任务在吃掉你的 GPU 内存,应该怎样调整,使 LLM 适应你的 GPU?
那么,我们应该怎样使用这个工具呢?
首先,你需要处理模型的名称、ID 和大小。你可以输入 Huggingface 上的模型 ID(比如 meta-llama/Llama-2-7b)。目前,这个项目已经内置了 Huggingface 上下载次数最多的 top 3000 LLM 的模型配置。如果你使用的是自定义模型,或者 Huggingface ID 不可用,那么你可以上传 json 配置(参考项目示例),或者直接输入模型大小(比如 llama-2-7b 是 70 亿)。
接下来是量化。目前,这个项目支持 bitsandbytes (bnb) int8/int4,以及 GGML(QK_8、QK_6、QK_5、QK_4、QK_2)。后者只用于推理,而 bnb int8/int4 可用于训练和推理。
最后是推理和训练。在推理阶段,你可以使用 HuggingFace 实现,或者使用 vLLM、GGML 方法找到用于推理的 vRAM;在训练阶段,你可以找到 vRAM 对全模型进行微调,或者使用 LoRA(目前项目已经为 LoRA 配置硬编码 r=8)、QLoRA 进行微调。
但需要注意的是,最终的结果可能会有所不同,这取决于具体的软件版本、操作系统以及其他一些你的系统特定的因素。比如,你的系统可能需要更多的内存来管理 CUDA 上下文,或者你的深度学习框架可能会在 GPU 上预先分配一些内存。因此,这个工具提供的内存估计应该被看作是一个近似值。
项目的地址在这里:
htxxps://github.com/RahulSChand/gpu_poor
交互地址是:
htxxps://rahulschand.github.io/gpu_poor/


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






