一张照片就能让马斯克、梅西等各大名人魔性跳舞,甚至连火爆全网的科目三都能安排上。这可不是什么高深 AI 技术,阿里通义千问移动端新增的全民舞王功能就能实现,还有科目三、DJ 慢摇、鬼步舞、极乐劲舞等 12 种热门舞蹈模版供你挑选。在通义千问输入「全民舞王」「通义舞王」等口令,接着在跳转界面里选择你喜欢的舞蹈、上传一张全身照,只需十几分钟,一个形神兼备的舞王就这样华丽「速成」了。
想不到,浓眉大眼的爱因斯坦也能秒变潮男,动作节奏感简直不要太强。

兵马俑和舞王只差了一张照片,这架势可不是盖的。

手办届的舞王称霸,怎么能忽视我「亚洲舞王」尼古拉斯赵四呢?

随手一画的小人物都跳得比我还欢,看来我得去报个舞蹈班才行。
那阿里的 AI 研究团队是怎么让照片动起来的呢?
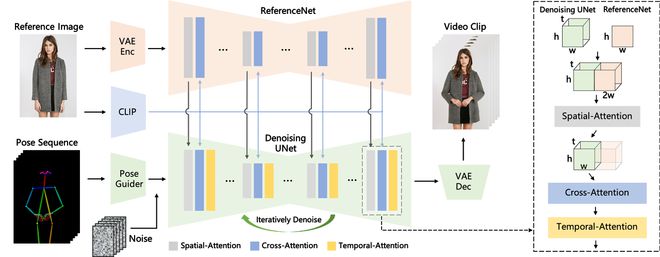
通义舞王功能的发布,实际上是 AnimateAnyone 技术的一个具体应用和落地。据阿里 AI 研究团队发布的论文介绍,目前,扩散模型是视觉生成研究领域的主流,但在图像到视频的生成领域中,依然存在局部失真、细节模糊、帧率抖动等问题。对此,阿里的 AI 研究团队在扩散模型的基础上,提出了一种新的 AI 算法 Animate Anyone。这个算法的功能是将一个静态的人物图像转换成一个动画视频,同时可以通过输入姿势的顺序来精确控制视频中的人物动作。
 ▲手翻书原理展示. 图片来自:@翻页书安迪Andymation
▲手翻书原理展示. 图片来自:@翻页书安迪Andymation
需要说明的是,在视频制作特别是动漫制作中,人物的动作是通过逐帧过渡完成的,原理类似于小时候经常玩的手翻书,每一页都是静态的手绘稿,快速翻动就能通过人眼「视觉暂留」的 BUG 让画面动起来。
而想要让一张图片动起来,最大的难点来自「脑补」接下来的动作和场景,并且前后都没有参照物。所以官方的对比展示中,可以看到传统技术「DisCO」被作为反面教材反复鞭打,其严重的失真效果只能做到让主体动起来,但扭曲的身型和奇怪的动效完全称不上作品。

因此,为了解决视频人物形象一致性的问题,他们引入了参考图像网络 ReferenceNet,它可以捕获参考图像中的空间细节信息。
然后,他们将 ReferenceNet 与 UNet 结合,让 UNet 可以理解在生成目标图像时应该在哪些位置生成怎样的细节,这样就可以使生成的图像在整体上去除噪音的同时,保留参考图像中的关键细节,实现人物形象的一致性。除了细节的捕捉以外,还要确保姿态的可控性。为此,阿里 AI 团队还设计了一种轻量级的姿态引导器 Pose Guider,在去噪过程中集成姿态控制信号,以确保生成的动画序列符合指定的姿态。
考虑到视频的稳定性问题,他们还引入了时序生成模块,目的是让模型可以学习帧与帧之间的联系,这样生成的视频才会流畅连贯,而不是割裂开来,同时还可以保持高分辨率细节,让画质变得更好更稳定。
比起以前的方法,该方法能够有效保持了视频人物外观的一致性,不会出现诸如衣服颜色变来变去等问题,同时视频流畅清晰,不会闪烁抖动,并且还支持对任意角色进行动态化。
例如,梅西玩转中老年最爱的顶流范儿,和你抬手打招呼。

二次元角色以静化动,跳起宅舞来丝毫不逊色真人。

连钢铁侠都加入热闹,一起强身健体,活动活动筋骨,也没啥毛病。
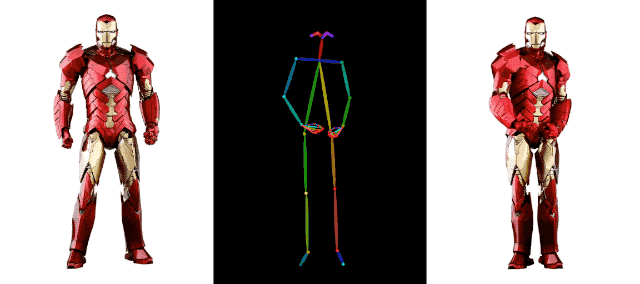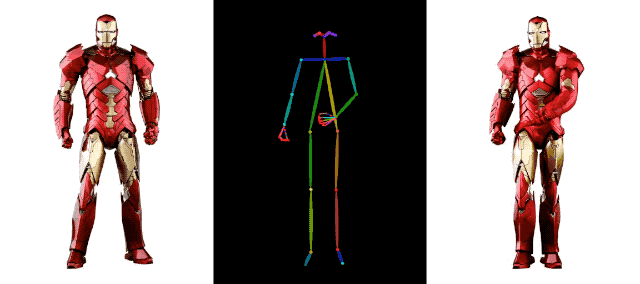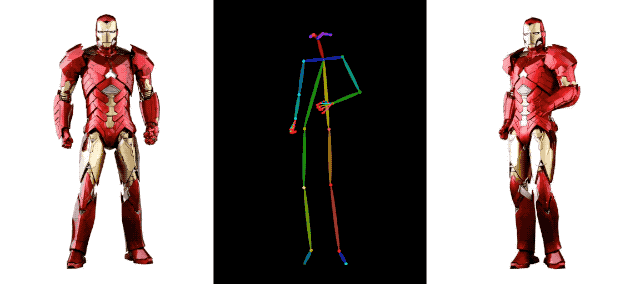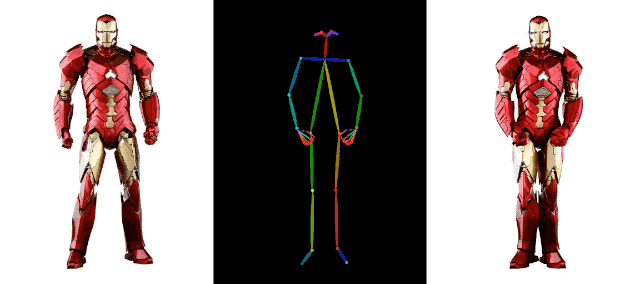
在 AI 视频生成领域,阿里背后的技术积累远不止这些,比如上个月,阿里还发布了另一项视频生成技术 DreaMoving。这是一种基于扩散的可控视频生成框架,用于生成高质量的定制化人像视频。
这项技术的优势在于,无需深入了解复杂的视频制作技术,使用者只需给定一些引导,比如一段文字或一张参考图像,DreaMoving 就能够创造出高度逼真的视频。

也就是说,只要给定目标身份和姿势序列,DreaMoving 可以根据姿势序列生成,任何人/物在任何地方跳舞的视频。
简单点理解,DreaMoving 可以通过简单的输入,比如人脸图片、动作序列和文本,就可以自动生成各种定制化的人物视频,实现对视频生成的精确控制。
具体的拆解步骤:先输入一个人的面部图片,来生成这个人的整个身体在视频中的形象,接着输入姿势的顺序,来精确控制人物在视频里的动作,最后输入文本来更全面地控制视频的生成效果。
AI 视频生成行业卷疯了
事实上,在生成式 AI 的赛道中,AI 视频生成领域的起点并不算太晚,在 ChatGPT 横空出世之前,就已经有不少厂商押注该赛道,诸如微软、Google 等都曾推出过类似的 AI 视频生成工具的,但效果甚微。
立足于整个行业长期的技术积累之上,扩散模型的出现让厂商们看到了 AI 视频生成的潜在前景。相比 RNN 等早期模型有明显优势,它可以生成更连贯、清晰的图像或视频序列,加速了视频生成的迭代过程。
市面上的主流工具也在此基础上大作加法,让 AI 视频生成赛道再起波澜,真正呈现出惊人的爆发之势。

去年年底,Runway Gen-2 迎来一波大更新,分辨率提升至 4K,视频生成效果的保真度和一致性迎来重大突破,一周后,又再次推出运动画笔功能,轻轻一刷,便能让静态事物动起来。紧接着,文生图的「扛把子」Stability AI 也发布 Stable Video Diffusion,给 AI 视频生成领域再添一把旺火。
而 Pika 1.0 则凭借更简单的视频生成,浅显易懂的视频局部编辑,更高质量的视频生成,刚出道便获得一众硅谷大佬的青睐。从生成到后期,仅靠自己就能完成一条龙操作。

李飞飞团队和 Google 合作推出的 W.A.L.T 模型,也同样可以根据自然语言/图片提示,生成逼真的 2D/3D 视频或动画,生成效果更是媲美 Runway、Pika 等一众好手。

这些 AI 视频生成工具主要在两个维度上有了长足进步——质量和数量。在质量上,这些 AI 产品不断引入更强大的模型架构,使用更大规模、更高质量的数据进行训练,使得 AI 生成的视频画质、流畅度、逼真度等都在持续提升。在数量上,生成的视频长度也在不断内卷,朝着两位数的秒数长度突破,场景和事件组合也日益丰富。未来在算力进一步提升的情况下,生成长达数小时的高质量视频也将成为可能。
飘在云上的技术终究还是落地应用,AI 视频生成的崛起将会诞生一个巨大的蓝海市场。依托技术的深厚积累,通义千问的「全民舞王」的上新,也是基于这套商业逻辑的又一落地产物。
这不仅可以打开与阿里与其他企业的竞争,促使整个行业加速进步,也让我们有机会亲身体验更多 AI 视频生成技术所带来的种种可能。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






