

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

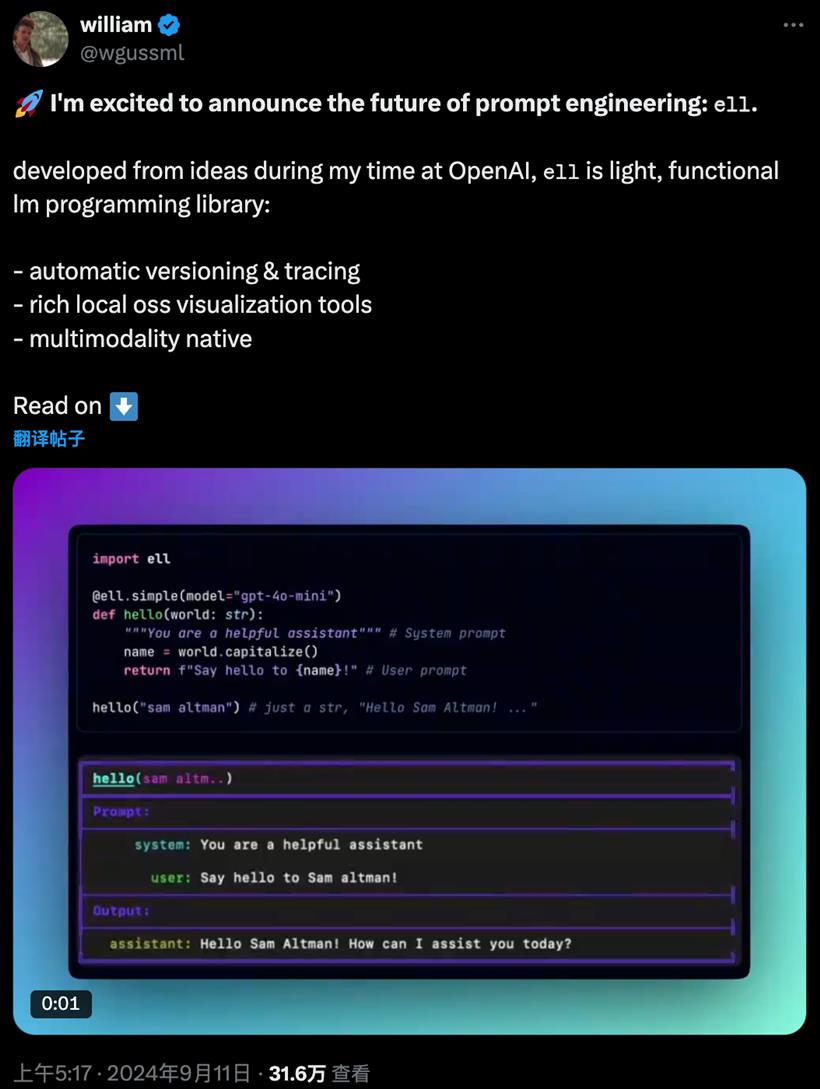
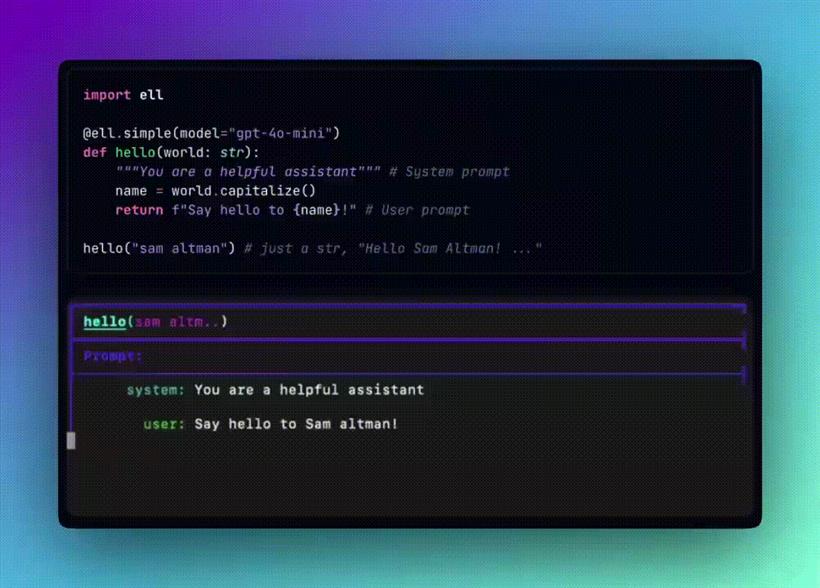
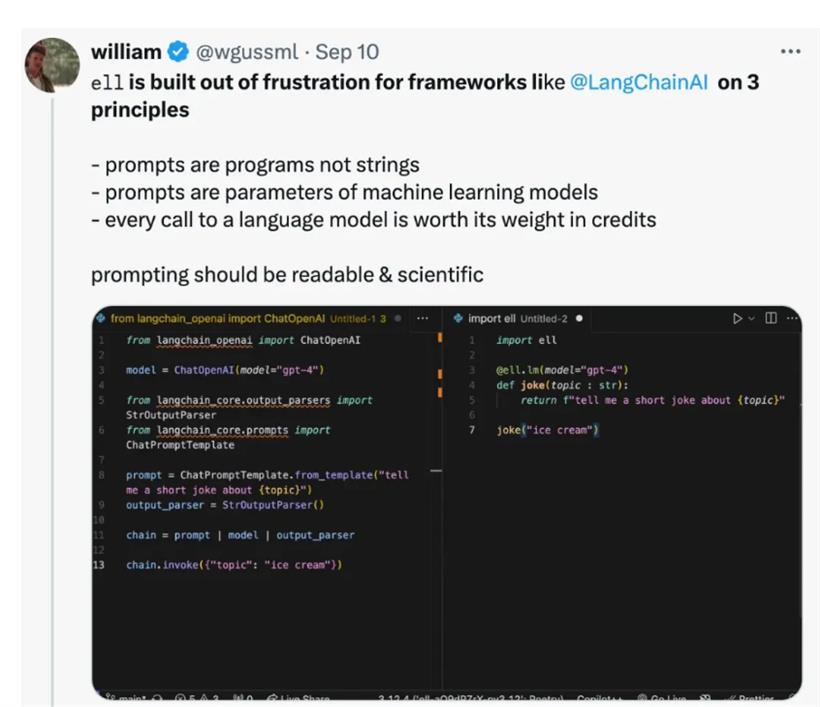
import ell
from dotenv import load_dotenv
from openai import OpenAI
import os
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 堆代码 duidaima.com
@ell.simple(model="gpt-4o-mini", client=client)
def hello(world: str):
"""You are a helpful assistant""" # System prompt
name = world.capitalize()
return f"Say hello to {name}!" # User prompt
print(hello("sam altman"))
这是我得到的响应: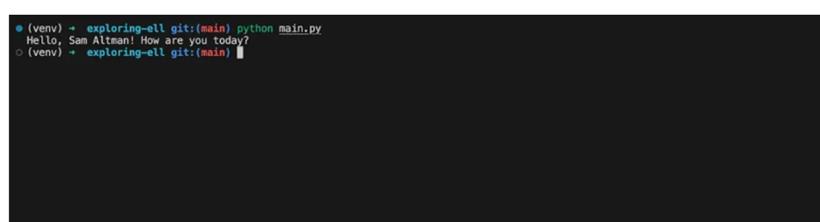
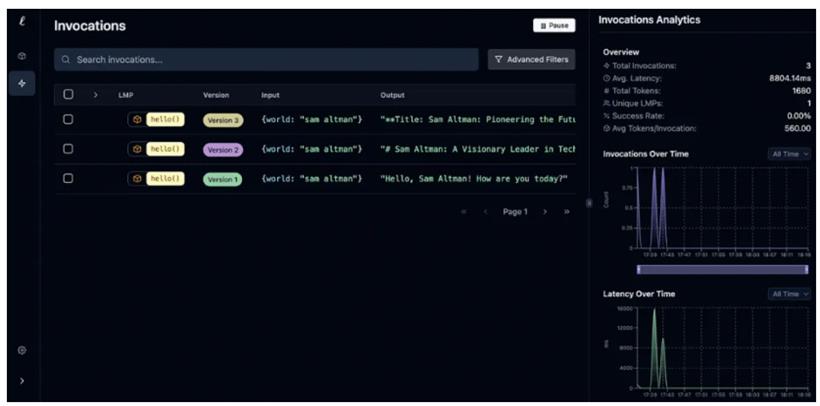

import ell
from dotenv import load_dotenv
from openai import OpenAI
import os
import requests
# Load environment variables
load_dotenv()
# Initialize ell logging store
ell.init(store='./logdir')
# Initialize OpenAI client
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# Define a tool to search on the internet using SERPAPI
@ell.tool()
def search_on_internet(query: str) -> str:
search_url = "https://serpapi.com/search"
params = {
"q": query,
"api_key": os.getenv("SERPAPI_API_KEY"),
}
response = requests.get(search_url, params=params)
if response.status_code == 200:
data = response.json()
if "organic_results" in data:
results = data["organic_results"][:3]
text = results[0]["snippet"] if results else "No snippet available"
final = {
"results": results,
"text": text
}
return f"Top 3 results: {final['results']}\n\nText: {final['text']}"
else:
return "No results found."
else:
return f"Error fetching search results: {response.status_code}"
# Define a complex task using ell and GPT model
@ell.complex(model="gpt-4o-mini", client=client, tools=[search_on_internet])
def article(country: str):
"""You are a helpful assistant""" # System prompt
name = country.capitalize()
return f"Who is the president of {name} in 2024?" # User prompt
# Test the function
print(article("united states"))
注意:如果使用 Ell 的最新版本,它现在可以工作了。import ell
from dotenv import load_dotenv
from openai import OpenAI
import os
import requests
# Load environment variables
load_dotenv()
# Initialize ell logging store
ell.init(store='./logdir')
# Initialize OpenAI client
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# Define a tool to search on the internet using SERPAPI
@ell.tool()
def search_on_internet(query: str) -> str:
search_url = "https://serpapi.com/search"
params = {
"q": query,
"api_key": os.getenv("SERPAPI_API_KEY"),
}
response = requests.get(search_url, params=params)
if response.status_code == 200:
data = response.json()
if "organic_results" in data:
results = data["organic_results"][:3]
text = results[0]["snippet"] if results else "No snippet available"
final = {
"results": results,
"text": text
}
return f"Top 3 results: {final['results']}\n\nText: {final['text']}"
else:
return "No results found."
else:
return f"Error fetching search results: {response.status_code}"
# Define a complex task using ell and GPT model
@ell.complex(model="gpt-4o-mini", client=client, tools=[search_on_internet])
def article(country: str):
"""You are a helpful assistant""" # System prompt
name = country.capitalize()
return f"Who is the president of {name} in 2024?" # User prompt
# Test the function
output = article("united states")
if output.tool_calls:
print(output.tool_calls[0]())
多模态是头等公民import ell
from dotenv import load_dotenv
from openai import OpenAI
import os
from PIL import Image
# Load environment variables
load_dotenv()
# Initialize ell logging store
ell.init(store='./logdir')
# Initialize OpenAI client
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
@ell.simple(model="gpt-4o", client=client)
def describe_activity(image: Image.Image):
return [
ell.system("You are VisionGPT. Answer <5 words all lower case."),
ell.user(["Describe the content of the image:", image])
]
# Load Image
img = Image.open("product_2.jpg")
# desc
print(describe_activity(img))
我得到的结果相当准确。你可以看看这里: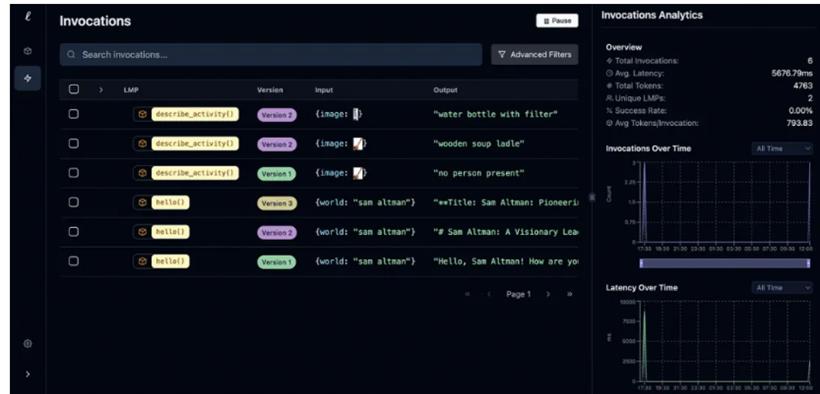
from pydantic import BaseModel, Field
import ell
from dotenv import load_dotenv
from openai import OpenAI
import os
# Load environment variables
load_dotenv()
# Initialize ell logging store
ell.init(store='./logdir')
# Initialize OpenAI client
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
class MovieReview(BaseModel):
title: str = Field(description="The title of the movie")
rating: int = Field(description="The rating of the movie out of 10")
summary: str = Field(description="A brief summary of the movie")
@ell.complex(model="gpt-4o-2024-08-06", client=client, response_format=MovieReview)
def generate_movie_review(movie: str) -> MovieReview:
"""You are a movie review generator. Given the name of a movie, you need to return a structured review."""
return f"generate a review for the movie {movie}"
然后我想到了构建一个合成数据生成器。生成器以公司名称为输入,并为该公司生成合成员工。相当酷吧?这只是众多潜在用例中的一个。你可以想象使用这种结构化输出生成功能构建一个金融分析师 Agent 或国际象棋 Agent。from pydantic import BaseModel, Field
import ell
from dotenv import load_dotenv
from openai import OpenAI
import os
# Load environment variables
load_dotenv()
# Initialize ell logging store
ell.init(store='./logdir')
# Initialize OpenAI client
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# Define your desired output structure
class Employee(BaseModel):
name: str
position: str
department: str
hire_date: str
salary: int
@ell.complex(model="gpt-4o-2024-08-06", client=client, response_format=Employee, n=10)
def generate_synthetic_data(company: str) -> list[Employee]:
""""""
return f"generate employees for this company: {company}"
for employee in generate_synthetic_data("Nebius"):
print(employee.parsed)
总结




