

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

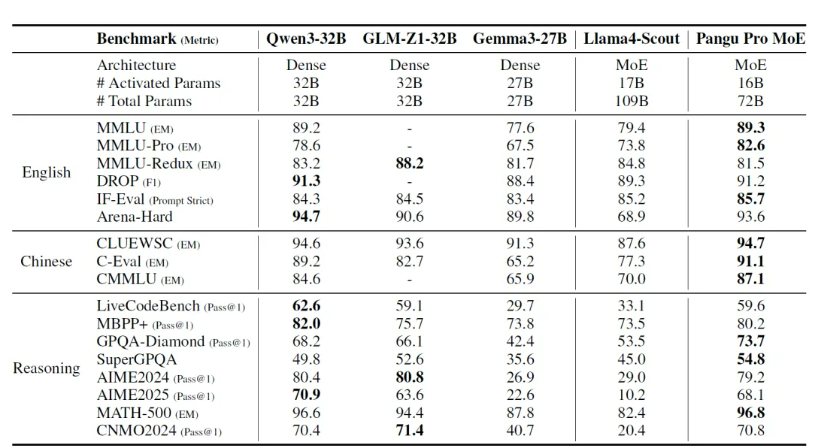
日前,华为盘古团队正式公布了昇腾原生的分组混合专家模型——「盘古 Pro MoE」。据盘古团队介绍:混合专家模型(MoE)在大语言模型(LLMs)中逐渐兴起,该架构能够以较低计算成本支持更大规模的参数,从而获得更强的表达能力。这一优势源于其稀疏激活机制的设计特点,即每个输入 token 仅需激活部分参数即可完成计算。然而,在实际部署中,不同专家的激活频率存在严重的不均衡问题,一部分专家被过度调用,而其他专家则长期闲置,导致系统效率低下。
为此,盘古团队提出了新型的分组混合专家模型(Mixture of Grouped Experts, MoGE),其在专家选择阶段对专家进行分组,并约束 token 在每个组内激活等量专家,从而实现专家负载均衡,显著提升模型在昇腾平台的部署效率。
性能表现上,盘古 Pro MoE 在昇腾 800I A2 上实现了单卡 1148 tokens/s 的推理吞吐性能,并可进一步通过投机加速等技术提升至 1528 tokens/s,显著优于同等规模的 320 亿和 720 亿参数的稠密模型;在昇腾 300I Duo 推理服务器上,盘古团队也实现了极具性价比的模型推理方案。





