“语言是人类交流的工具,而非思维的载体。”
模型越大,参数越多,能力就越强。这套“规模定律”(Scaling Law)就像武林秘籍,仿佛只要算力管够,就能一路莽到通用人工智能(AGI)的彼岸。然而,就在大家习惯了这种“大力出奇迹”的玩法时,总有人想打破规矩。2025年的夏天,一家来自新加坡的初创公司Sapient Intelligence(Sapient智能)带着他们的新作HRM(Hierarchical Reasoning Model,分层推理模型)走上台前,轻轻一挥手,就给整个行业带来了亿点点震撼。这个模型只有区区2700万(27M)参数,个头还没现在主流大模型的零头大,却在多项高难度推理任务上,把那些几百上千亿参数的“大块头”们按在地上摩擦。
通往AGI的道路,或许不只有堆砌算力这一条。
大模型“脑子不够用”的老大难,是如何被绕过去的?
这事儿得从头说起。我们现在熟知的GPT、Claude这些大语言模型(LLM),它们底层的Transformer架构,这东西的计算深度是固定的。打个比方,它就像一个流水线工厂,不管任务多复杂,都得在固定的工序内完成。这导致它们在处理一些需要反复琢磨、迭代计算的问题时,显得力不从心。
为了解决这个“推理困境”,研究员们想出了一个叫“思维链”(Chain-of-Thought, CoT)的法子。简单说,就是强迫模型把解题的每一步都写下来,像小学生做应用题一样,一步步引导自己思考。这法子管用是管用,但毛病也不少。首先,这个解题步骤得人来设计,一旦中间哪一步想错了,整个推理链就“翻车”了。其次,训练这种能力需要海量的标注数据,费钱费力。最后,每一步都生成一大堆文字,响应速度慢得像“老牛拉破车”,急死个人。
Sapient团队偏不信这个邪。他们觉得,人类思考复杂问题时,也不是一直在脑子里跟自己碎碎念的。很多时候,灵感和思路是在一个无声的、抽象的“潜空间”里碰撞出来的。正如他们在论文里说的:“语言是人类交流的工具,而非思维的载体。” AI为什么不能也学会在自己的“潜意识”里完成推理呢?于是,他们把目光投向了最高效的智能体——人脑。
给AI装个“大脑”,这事儿是怎么做到的?
HRM的核心创新,就是模仿了我们大脑的分层工作机制,搞了一套“双模块循环架构”。你可以把它想象成给AI装上了一个简易版的“大脑皮层”。
一个叫“高层模块(H)”,扮演着“CEO”的角色,类似大脑的前额叶皮层。它想得慢、想得深,负责制定全局战略和长期规划,确保整个推理过程方向不出错。
另一个叫“底层模块(L)”,扮演着“执行者”的角色,类似感觉运动皮层。它转得快、算得细,负责处理眼前的具体计算和局部优化,把CEO的战略一步步落实。
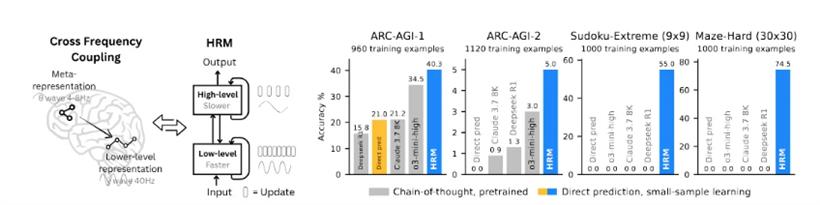
这两个模块不是各干各的,而是以不同的“时钟频率”协同工作。L模块在前面“吭哧吭哧”快速计算好几步后,H模块才不紧不慢地更新一次,根据最新进展调整一下大方向。这种被称为“分层收敛”(Hierarchical Convergence)的机制,巧妙地避免了传统循环网络容易“想太快”而陷入局部最优的问题,让模型既能深思熟虑,又能快速执行。
在训练上,HRM也搞了个大新闻。它用一种叫“单步梯度近似”的方法,取代了传统循环网络那个极其消耗内存的“通过时间反向传播”(BPTT)技术。这就好比,以前的AI学东西,需要把整个学习过程的所有步骤都记在脑子里,复盘起来内存直接爆炸。现在HRM学会了“边学边改”,内存占用从O(T)直接降到了O(1),训练效率大大提升,也更符合大脑的运作方式。
HRM到性能如何?
为了证明HRM不是在“画大饼”,Sapient团队把它拉到了几个业界公认的“考场”上,和一众主流大模型真刀真枪地比试了一番。首先是ARC-AGI基准测试,这玩意儿被看作是衡量通用人工智能能力的“试金石”,专门考那种需要归纳和抽象推理的难题。HRM在只用了区区约1000个样本进行训练的情况下,用它27M的小身板,取得了40.3%的准确率,直接把一众参数和训练数据都比它多得多的前辈们给比了下去。
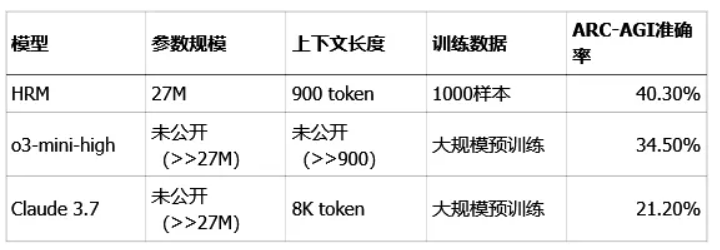 数据来源:arXiv:2506.21734
数据来源:arXiv:2506.21734
如果说ARC的胜利还不够直观,那在数独和迷宫这两个符号推理任务上,HRM的表现只能用“降维打击”来形容。面对“极端难度数独”和30x30的复杂迷宫寻路,即便是顶级的GPT-4和Claude 3,用上思维链(CoT)方法也是束手无策,准确率直接挂零。而HRM呢?在经过1000个样本训练后,几乎是闭着眼睛拿到了满分。
 数据来源:arXiv:2506.21734
数据来源:arXiv:2506.21734
为什么会这样?一张对比图揭示了真相。对于Transformer架构来说,单纯增加模型的宽度(参数量)对解这类难题帮助不大,增加深度虽然有点用,但很快就会遇到瓶颈。而HRM凭借其独特的循环“大脑”结构,成功地将计算深度线性扩展了出去,突破了这层天花板。
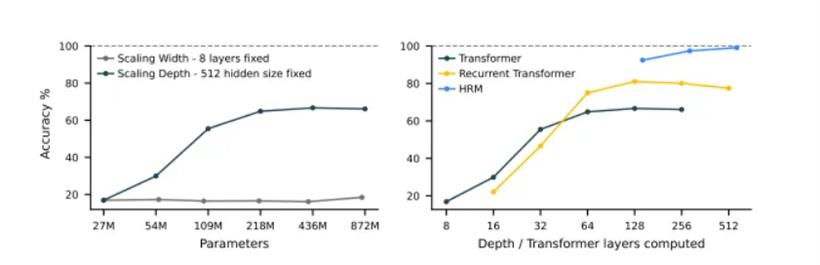 左:Sudoku-Extreme Full(数独极限)任务上,增加Transformer宽度无益,增加深度关键但会饱和;右:HRM克服深度限制,实现近乎完美准确率(来源:arXiv:2506.21734)
这群“屠龙少年”,到底什么来头?
左:Sudoku-Extreme Full(数独极限)任务上,增加Transformer宽度无益,增加深度关键但会饱和;右:HRM克服深度限制,实现近乎完美准确率(来源:arXiv:2506.21734)
这群“屠龙少年”,到底什么来头?
搞出这么大动静的Sapient Intelligence,是一家成立于新加坡的AI“新势力”。团队阵容堪称豪华,核心成员汇聚了来自Google DeepMind、DeepSeek、Anthropic、xAI等顶尖AI机构的大牛,以及剑桥、清华、北大等世界名校的学霸。
创始人兼CEO王冠(Guan Wang),是清华大学计算机学士,也是著名开源模型OpenChat的作者,这款70亿参数的模型性能曾超越70B的LLaMA2,在GitHub上狂揽超5400星。联合创始人陈威廉(William Chen)同样毕业于清华,曾在大疆创新、禾赛科技等公司担任研发负责人。更难得的是,这群技术大牛还有着开放的极客精神。果断开源HRM模型,并建立了社区,邀请全世界的开发者一起来探索类脑推理的未来。GitHub上星标已突破10.3k。
GitHub:https://github.com/sapientinc/HRM


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






