随着ChatGPT等模型被广泛应用,用户对功能的需求也呈多模态发展,例如,在单一模型上既能生成文本也可以生成图片等。但现有视觉模型通常仅针对单一模态和任务进行优化,缺乏能够处理多种模态和任务的通用能力。为了解决这一难题,苹果的研究人员和全球著名公立大学EPFL(瑞士洛桑联邦理工学院)联合开发了4M框架并即将开源。4M可以把多种输入/输出模态,包括文本、图像、几何、语义模态以及神经网络特征图等,全部集成在大模型中(适用于Transformer架构)。
项目地址:
https://4m.epfl.ch/
论文地址:
https://arxiv.org/abs/2312.06647
4M技术原理简单介绍
相比以往单一模态下的深度学习方法,4M最大的技术亮点在于使用了一种名为"Massively Multimodal Masked Modeling"(大规模多模态屏蔽建模)的训练方法。可以同时处理图像、语义、几何等各类视觉模态,将影像、字幕、框架信息等,都能以离散 tokens 的形式完美“翻译”出来,实现各模态在表示空间上的统一。为确保tokens之间协调一致,4M还在注意力机制中加入模态区分,禁止不同模态之间互相影响。同时4M训练采用掩码重建目标,实际上相当于进行模态间的预测编码。
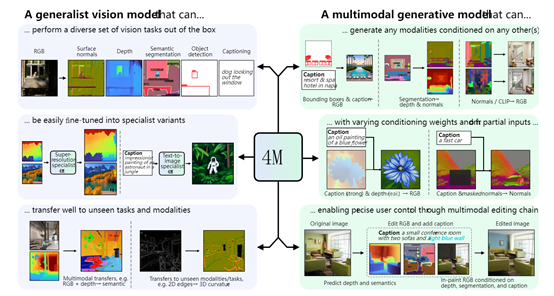
在训练过程中,模型会随机选择一小部分标记作为输入,另一小部分标记作为目标,通过解耦输入和目标标记的数量与模态数量的关系,实现了可扩展的训练目标。简单来说,无论用户输入的内容是图片还是文本,对于4M来说都是一串标准化的数字标记。这种“通用语言”设计有效阻断了各模态特有信息对模型架构的影响,极大提升了模型的通用性。
训练数据和方法
4M将在训练过程中使用了全球最大的开源数据集之一CC12M,包含图像、深度图、语义信息、文本等各类数据集。虽然CC12M的数据很多,但缺乏准确的标注信息。为了解决这个难题,研究人员使用了一种高效、成本又低的方法——弱监督伪标签。这个与前几天OpenAI开源的超级对齐方法很相似。

通过利用CLIP、MaskRCNN等技术,对CC12M的图像数据集进行全面预测,然后得到语义、几何及视觉特征等丰富模态信息。再使用转换“翻译”模块将所有伪标签信息,统一转化为离散表示的“tokens”。这为4M在不同模态之间实现统一的兼容奠定基础。研究人员在广泛的实验和基准测试平台中对4M进行了测试,可以直接执行多模态任务,而无需进行大量的特定任务预训练或微调。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






