一、模型推理优化
随着模型在各种场景中的落地实践,模型的推理加速早已成为AI工程化的重要内容。而近年基于Transformer架构的大模型继而成为主流,在各项任务中取得SoTA成绩,它们在训练和推理中的昂贵成本使得其在合理的成本下的部署实践显得愈加重要。
大模型推理所面临的挑战主要有以下两点:
1.巨大的内存(显存)需求,主要来自于模型本身参数和推理的即时需求。
对于一个LLaMA2-30B的模型,载入显存其模型本身需要约60GiB的显存,推理过程中,单个token的KV cache 需要1.6MiB左右的显存:6656(layer dim) * 52(layer num) *2 (K & V) * 2(fp16, 2bytes);对于一个2048个token的请求则需要3.3GiB的显存。
2.并行性较差,因为生成过程通常在时序上是一个串行的过程,导致decoding的过程较难并行,成为计算的瓶颈。
常见的推理优化方式有知识蒸馏(Knowledge Distillation,KD),剪枝(Pruning)和量化(Quantization),以及针对LLM的内存优化而提出的各种方案(如Flash Attention、Paged Attention等)。
蒸馏指通过直接构造小模型,作为学生模型,通过软标签与原标签结合的方式监督学习原模型的知识,从而使小模型具备与原模型相当的性能,最终用小模型代替大模型从而提高推理效率。
剪枝则是通过靠剪除模型中不重要的权重从而给模型“瘦身”,提高模型的推理效率,为了保证模型的能力,通常剪枝过程也需要伴随着模型基于训练数据的微调。根据剪除权重的维度不同,可以分为结构化剪枝(structured pruning)和非结构化剪枝(unstructured pruning)。
结构化剪枝:通常按权重张量的某一或多个维度成块剪除不重要的通道,并保持正常的矩阵乘法;但因剪除的通道影响上下层的推理,需要检查网络的逻辑准确性。
非结构化剪枝:随机剪除权重张量中的不重要的元素,因而它通常会保持原本的权重结构,而造成稀疏的乘法计算,但并不能适配于通用的硬件,因而需要专用的硬件才能实现加速。
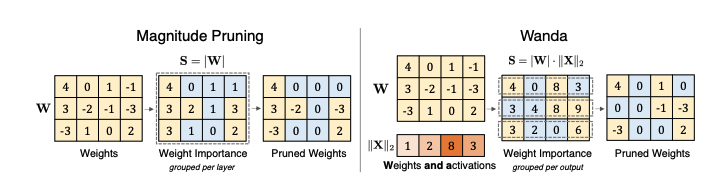
目前剪枝在LLM中的应用较少,如以下基于Activation-aware的剪枝工作[1],主要是基于权重本身的的绝对值大小和输入张量的绝对值大小做非结构化剪枝,使权重张量本身稀疏化,而模型的精度损失也并不能达到工程化的要求。
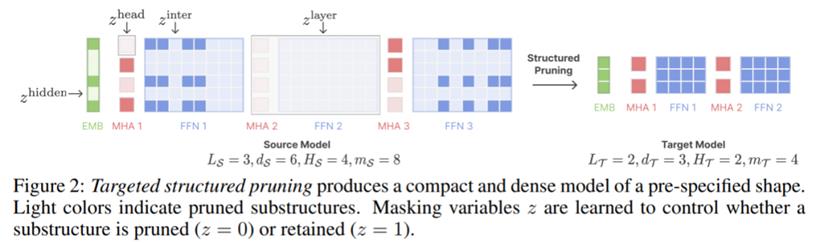
再如下图最近结构化剪枝的工作[2],通过搜索的方法寻找模型中的子结构,并通过重训练以保持模型精度,剪枝后的模型的精度相比原模型有很大的降低,只能跟同等参数量(剪枝后)的其他较小模型比较以显示其方法的意义。

而量化之所以会成为神经网络以及LLM的首选,主要有以下的优点:
1.降低显存的直观体现。
2.一般LLM权重用FP16存储,而权重量化为int4之后,则直观上体积减小为原本的1/4(实际可能由于embeddings不量化,内存分配等一些原因会稍多一些),对显存的资源需求大大降低。
3.W4A16、W8A16等算子的加速,从而提升计算速度。
二、量化简介
base
量化的本质通常是将模型的参数,或整个模型的推理过程从浮点转化为整型。
量化参数通常由 scale 和 zero-point两个值构成,前者为浮点,后者为整型。设x为一个张量(它可以为权重,也可以是推理的中间变量),其量化过程可以表示如下,
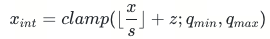
用b表示量化位宽,q{min}与q{max}分别表示整型值域的范围,例如int-8量化可以取[-128,127],即q{min}=-2^(b-1)=-128,q{max}=2^(b-1)-1=127,clamp(a;q{min},q{max})表示输入值a基于[q{min}, q{max}]范围的截断操作,x{int}表示量化后的结果,s和z表示量化参数scale和zero-point。
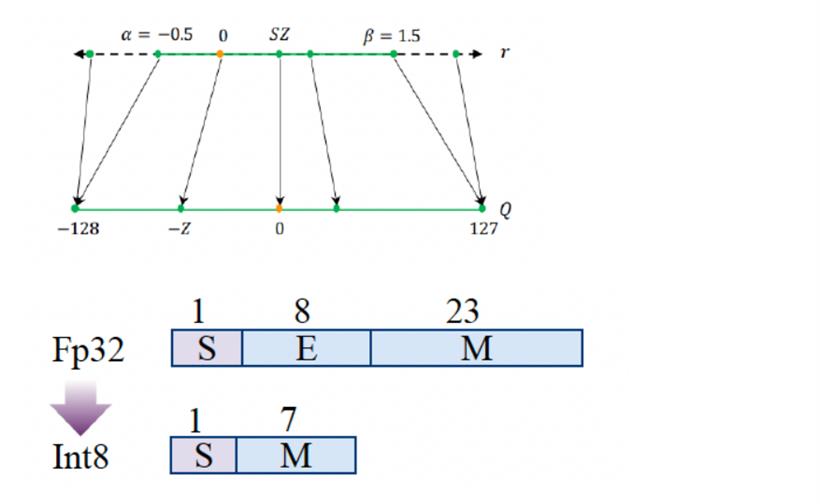
而从整型到浮点的反量化过程如下,
关于量化参数,有很多算法基于搜索,最优化,LKD(layer-by-layer 蒸馏)等各类算法计算其较优解,从而尽可能减少量化引起的精度损失;而最直接的计算scale 和方法即是基于张量元素min/max。
以下是一段简单的代码表示张量x从fp32量化到int8整型,再反量化回fp32的示例:
x->x{int}->x_hat的过程的一个示例如下:
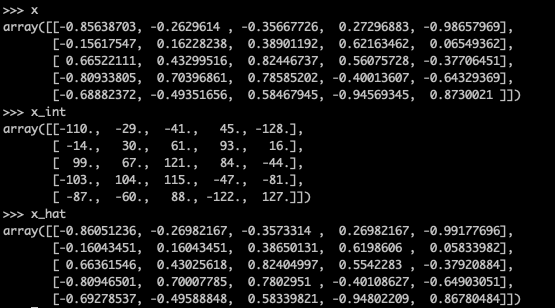
量化前x:

量化后x_hat:
 对称/非对称
对称/非对称
相比于非对称量化,对称量化的定义是量化所映射的整型值域基于0值对称,即上述公式的zero-point为0,qmax = -qmin,从而使量化的表达形式更为简化。
非对称量化有利于充分利用量化范围。例如Conv+ReLU输出的激励张量,其值皆为正值,若使用对称量化,则浮点将全部映射到[0~127]范围,有一半的范围未使用,其量化精度不如非对称量化。
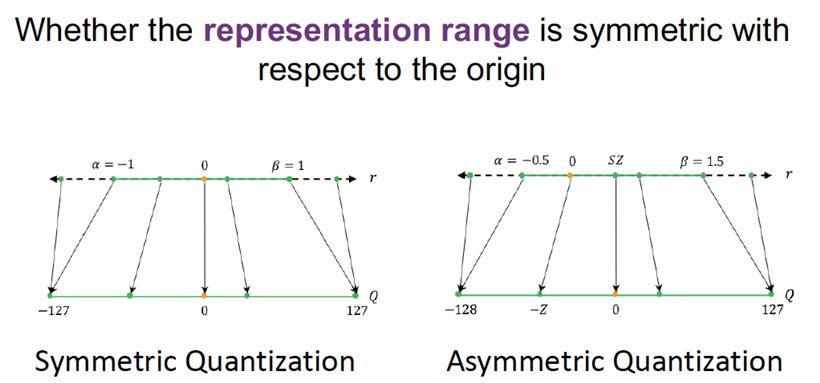
实际中往往选择对权重张量做对称量化,而对输入张量做非对称量化。以下是来自qualcomm 的量化白皮书中的分析,如权重和输入都选择非对称量化时,以Linear层的矩阵乘法为例,将表达式展开如下:
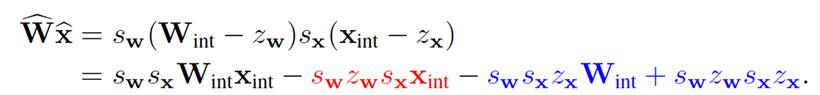
第一项是整型张量的乘法操作,是必须的即时操作;
第三、四项的操作包含了scale,zero和整型权重的乘法,这些都是提前预知的,因而可以事先计算作为偏置加上; -第二项的计算依赖x{int},是每次推理需要即时计算的,而这会造成额外算力。
因而当我们将权重量化改为对称量化时(zW=0),则上式简化为如下,即时计算时,只需要计算第一项的矩阵乘法,第二项是预先算好的偏置项:
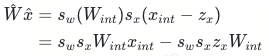
而当两者都是对称量化时的表达式,则简化如下:
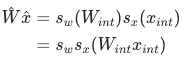
对比原模型中的浮点计算W{x},W{int}x{int}是整型与整型之间的乘法,后者在Nvidia GPU上的运算速度远快于前者,这是量化模型的推理速度大大加快的原因。
三、LLM的量化
Challenges in LLM Quantization
从模型表现的角度来讲,量化自始至终要解决的一个前提是,如何保持量化后模型的精度,即让模型的使用者觉得量化后的模型在推理效率提高的同时,还能保持原来的性能。
神经网络中需要量化的操作主要是卷积层Conv(x;W)和全连接层Wx,即主要是按上一部分描述的操作分别对W和x做的权重量化(Weight Quantization,WQ)和激励量化(Activation Quantization,AQ)。
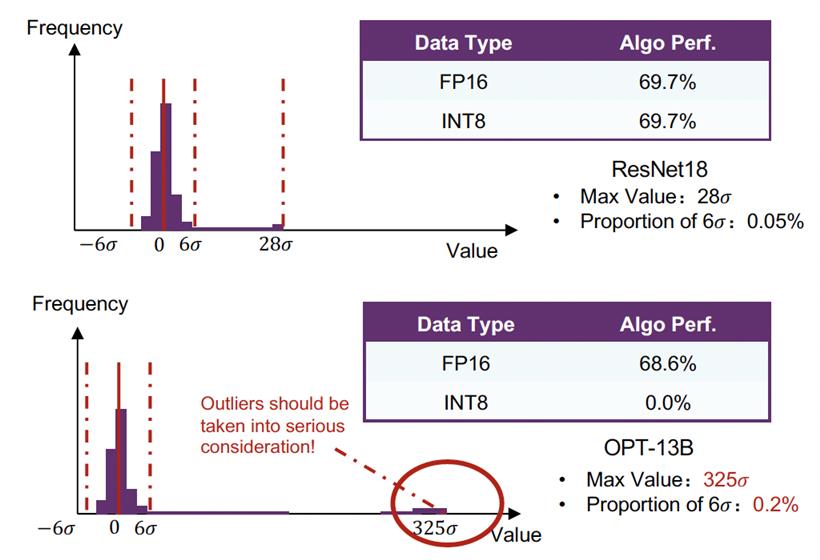
而不同于CNN模型或者小型Transformer模型,基于Transformer的大模型的矩阵乘法产生的激励张量通常有较多的离群值(outliers),即离值分布的大多数点形成的点群较远的值, 这些绝对值较大但占比较低的元素值增加了量化难度。而如何取舍outliers通常是量化工作中的一大难点,若过分考虑之,则会因量化范围过大而降低量化的表达范围,若过分截断之,通常会因这些绝对值较大的值,在模型推理中对结果有较大影响,而导致模型效果变差,而后者在LLM的量化则尤为明显。
下图分别是Resnet18与Opt-13B的某层输入张量的元素值统计,sigma表示各自分布的标准差,Resnet18输入的极大值约为28sigma,且绝对值6sigma以外的比例在0.05%;而Opt-13B网络输入的极大值越为325sigma,且绝对值6sigma以外的比例在0.2%。从量化效果而言,Resnet18的int-8精度基本无损失,而Opt-13B的int-8模型的精度已崩塌。
在应对激励量化的挑战这方面,有一些方案尝试降低量化精度,比如SmoothQuant提出的思路。
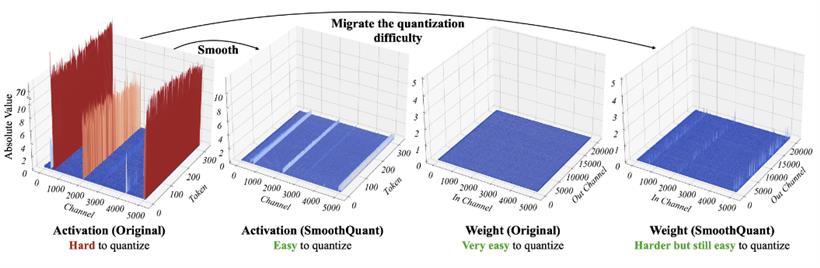
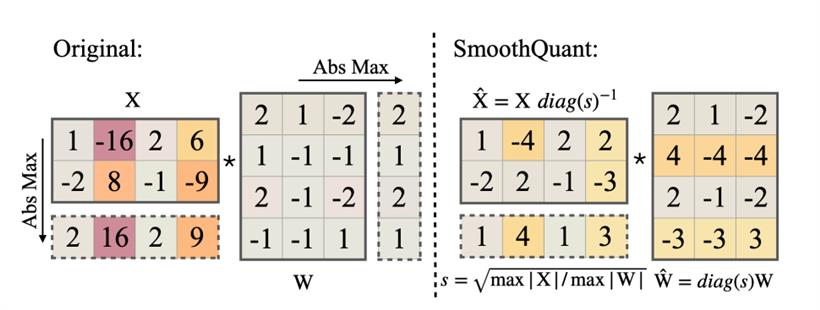
在矩阵乘法中,他们通过按比例缩小输入张量X的值,而将缩小的比例补偿给权重张量W,即把问题从量化X和W转化为了量化 X·diag(s^(-1))和diag(s)·W。从而在保证乘法运算的积保持不变的前提下,降低张量X的量化难度。而在实际工程中,这种量化方案引起的量化误差对大模型的推理效果仍然有比较明显的影响,即使在int-8精度量化亦有明显的误差。如以下对Llama2-7B的SmoothQuant应用结果显示其perplexity非常糟糕,难以在实际中应用。
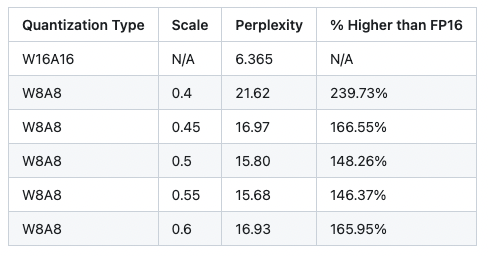
所以在目前工程部署中的实用方案,大多以weight-only的量化方案为主,即放弃activation的量化。
GPTQ
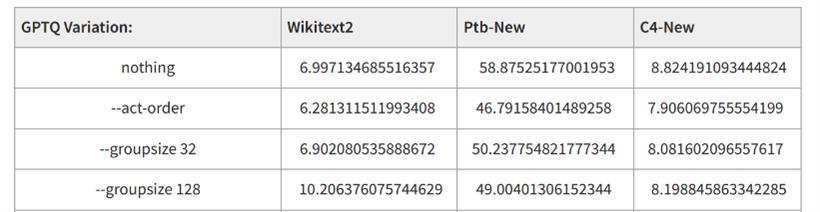
GPTQ是最早被工程化部署所接受的量化方案,W8A16或W4A16的量化效果在多数场景中都有与原模型较为接近的表现,而且其量化过程非常快。
量化过程
以矩阵乘法的基本单元操作为例,基于 weight-only量化前后的乘积的均方差,可以写出如下优化函数,
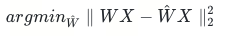
W 是在Transformer 中的Linear层权重,X表示其对应的输入。离线量化的过程是逐模块(Transformer)逐层(Q,K,V,O,Fc1,Fc2)做量化。
参数和数据定义如下:
W∈R^{K×M},X∈R^{M×N},Y=W×X∈R^{K ×N}
calibrate set:部分数据用作推理,用于查看各层输入张量的值范围,并基于此量化。
具体量化过程如下:
计算Hessian(上述优化函数对于W_hat的Hessian,而非反向传播中的Hessian),加入扰动项:
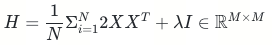
act order sort(desc_act,值范围相近的column一起做量化),基于diag(H)对W基于M维度作列重排,同理,对应地H在两个维度上重排。
求逆H^(-1)(cholesky分解)。
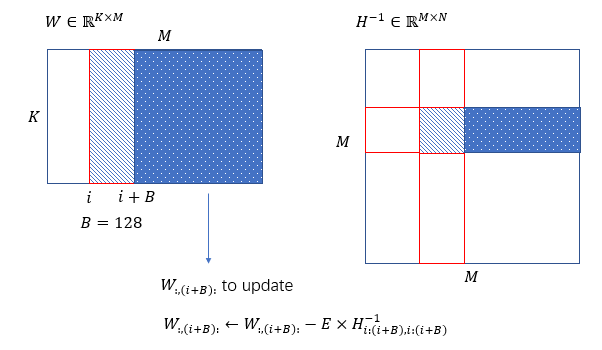
对W沿维度M,从左到右逐块量化,block size B=128,其右侧还未量化部分基于H^(-1)更新,以补偿量化损失。
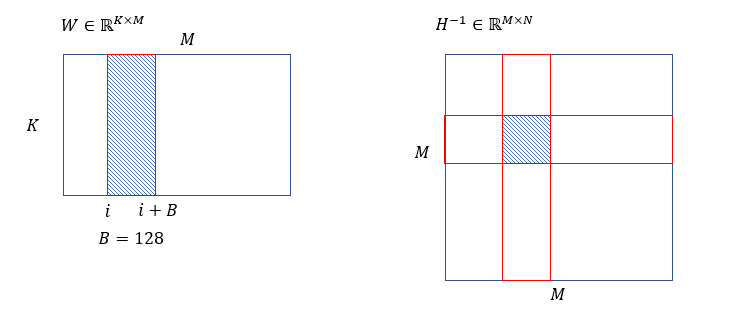
(inner loop)针对每个block内部,逐列量化,计算误差,并对该block内部未量化的列,基于误差更新。
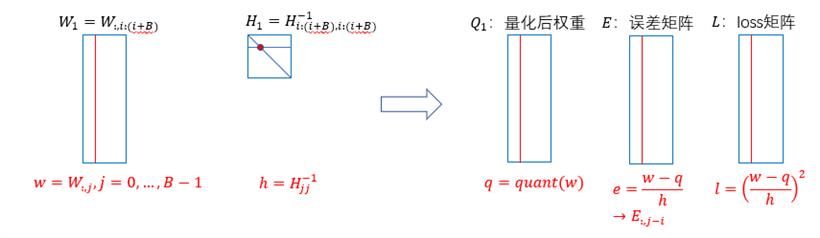

(outer loop)操作完该block,更新其后面的所有列:
 group_size
group_size
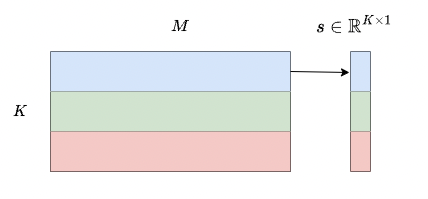
若不指定group size,默认g=-1,以所有列为单位统计量化参数,并对每一行的权重做量化,对于W∈R^{K×M},量化参数的数量为K×1。
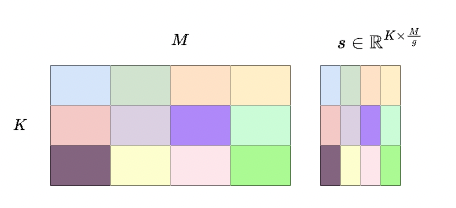
若指定group size,例如g=128,则会以每128列为单位统计量化参数,并对每一行的权重做量化,对于W∈R^{K×M},量化参数的数量为K×(M/g)。
 重排desc_act
重排desc_act
根据Hessian Matrix H,基于diag(H)对W基于M维度作列重排。其目的是优先量化绝对值较大的activaiton对应的weight的列,这些列在推理中被视为更为影响结果的重要的列,因而希望在量化这些列时尽可能产生较小的误差,而将更多的量化误差转移到后面相对不重要的列中。
部分实验表明desc_act对量化损失的效果在多数的任务中是有效的trick。
 算子
算子
严格来说基于weight-only的W4A16相比于原本的W16A16并没有太多效率的提升,而且推理中还加入了quant/dequant过程;而随着weight-only成为LLM量化的主流且应用越来越多,有很多开源的工作基于W4A16高效算子的编写为量化算法的推理提速赋能,比如GPTQ的python package AutoGPTQ已集成于开源工具exllama,后者基于triton和CUDA重写了量化乘法的并行计算。在exllama/exllama_ext/matrix.cuh可以看到dot_product8_h对out=W_hat·x=(W{int}-z)s·x=(W{int}-z)x·s的实现。
 AWQ
AWQ
相比于GPTQ从最优化问题出发设计方案,AWQ是基于搜索提出的量化方案。
用Q(·)表示量化反量化过程,则修改前的量化过程如下:
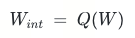
修改后,量化过程如下,加入了对W的缩放:
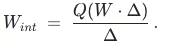 搜索
搜索
AWQ 的全称为Activation-aware Weight Quantization, 即对Weight的量化过程考虑Activation的值的影响。其出发点也是基于在Weight的各个通道中,处理对应的Activtion的值较大的通道则相对重要,反之则相对不重要,进而通过乘以一个缩放系数Δ去体现其重要性,而Δ的值和范围则通过输入的activation的张量值设计。

搜索的衡量标准依据Linear层量化前后输出结果的比较,取MSE结果最小者为最优解。
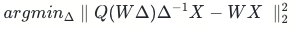 效果
效果
从模型表现效果方面,通过逐层 scale search 寻找最优的缩放系数,从而取量化误差最小的解,以下来自AWQ paper的效果比较,从Perplexity的角度,显示在两代Llama的测试上其量化结果稍优于GPTQ及GPTQ的排序版。
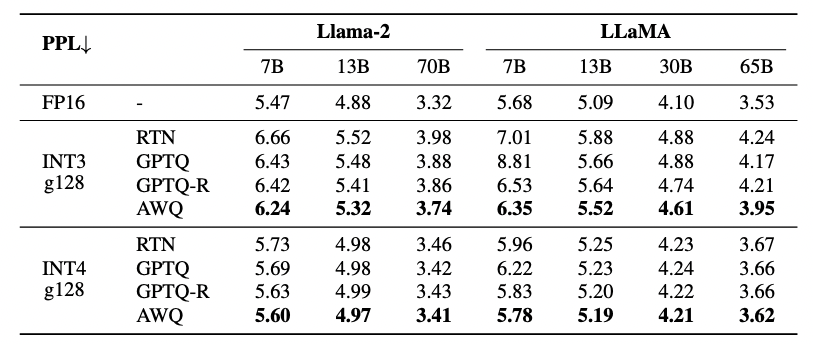
从实际任务的准确率来看,AWQ的准确率与GPTQ的act_order版本(GPTQ-R)相当,而速度优于后者。
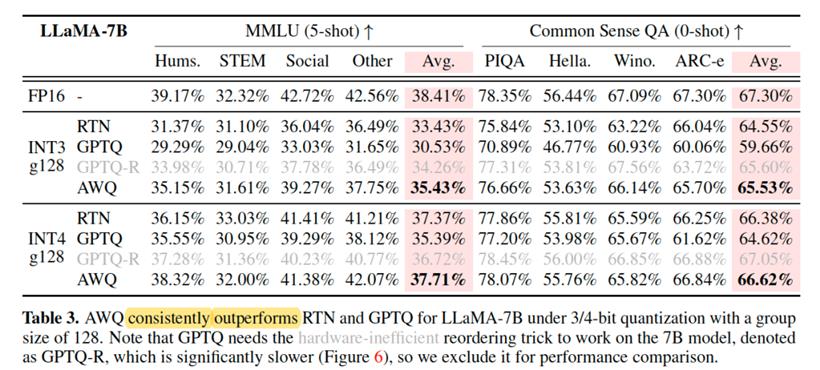
从模型的计算性能方面,GPTQ因为有reorder操作,矩阵乘法是MV(matrix×vector),为不连续的内存访问,而AWQ不存在reorder操作,矩阵乘法为(matrix×matrix),速度更快。
四、总结
关于LLM的量化工作目前的SOTA performance,基本上都是基于weight-only 的量化模式,模型在GPU运行所需的显存降低是其主要的贡献。从模型的表现来看,因为存在不可避免的量化损失,且LLM模型通常比传统的CNN模型对量化要敏感得多,虽然在很多任务上量化后的LLM表现与量化前差距不大,但是在一部分任务上可能依然无法胜任。
从模型的加速来看,weight-only的量化促使底层加速的工作基本上都在W4A16、W3A16、W8A16等乘法算子上的加速,从paper上提供的理论数据上来看通常相较于FP16模型只有 1.x ~3.x 倍速度的提升,而实际部署效果可能低于此数值,其加速效果远不如传统量化方法的W4A4、W8A8等全整型的乘法算子。
总体来说,LLM领域的量化工作还很初步,若在实际任务中对模型的表现精度要求十分高,更推荐单纯基于KV cache等方向提高单位显存吞吐量的算法和工具,如Flash Attention-2、Paged Attention等。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






