昨天,大模型赛道又迎来了一位重量级选手,小米宣布入局并上来就开源了一款大模型——MiMo-7B。虽然MiMo-7B只有70亿参数,但根据测试数据显示,MiMo-7B在数学AIME24/25中分别达到了68.2分和55.4分,超过了OpenAI的o1-mini以及阿里的QwQ-32B-preview;在代码LiveCodeBench v5中也达到了57.8分;在语言理解、科学问答和指令遵循等方面也非常出色。MiMo-7B是一款参数很小、消耗低、性能超强的模型,非常适合个人开发者和中小企业在本地部署使用。

开源地址:
https://huggingface.co/XiaomiMiMo
MiMo-7B架构简单介绍
MiMo-7B使用了标准的单向仅解码器Transformer架构,并结合了GQA、预RMS归一化、SwiGLU激活函数和RoPE技术来增强模型的推理能力。GQA技术能使模型在处理注意力机制时更高效,减少计算量的同时保持性能;RMS对输入进行归一化处理,有助于加速模型收敛并提高训练稳定性;SwiGLU激活函数增强了模型的表达能力,让其能更好地学习复杂的语义关系;RoPE则为模型提供了更好的位置编码,使其在处理序列中的位置信息时表现更好。
不过模型在推理过程中常面临推理速度瓶颈,尽管推理路径中连续token之间具有较高的相关性和可预测性,但冗长的自回归生成过程限制了推理速度。为解决这一问题,受DeepSeek-V3启发,MiMo-7B引入了MTP模块,并将其作为额外的训练目标。
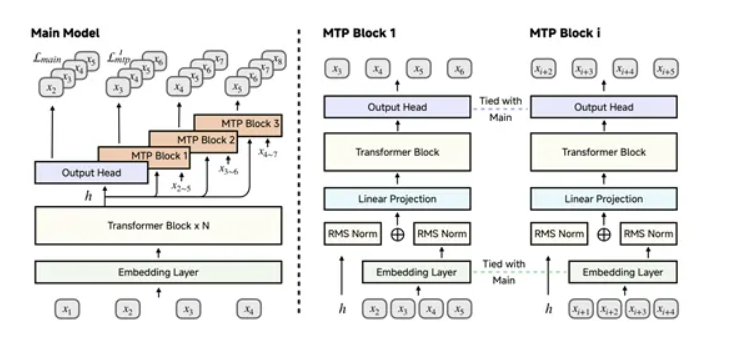
在预训练阶段,模型仅使用单个MTP层,而在推理阶段,通过复制预训练的MTP层并进行微调,可以显著加速解码过程。实验表明,第一个MTP层的接受率高达约90%,即使第三个MTP层的接受率也保持在75%以上,这使得MiMo-7B在需要极长输出的推理场景中能够实现更快的解码速度。
训练数据集
训练数据方面,MiMo-7B采用了多种策略生成合成推理数据。选择与STEM相关的内容,提示模型进行深入分析和思考;收集数学和代码问题,让模型尝试解决;并加入一般领域的查询任务,尤其是创意写作任务。实验表明,与非推理数据不同,合成推理数据可以在极高的训练周期下使用,而不会出现过拟合的风险。
为了优化预训练数据的分布,MiMo-7B采用了三阶段数据混合策略。在第一阶段,纳入了除推理任务查询的合成响应外的所有数据源,并对过代表的内容进行了降采样,同时对专业领域中的高质量数据进行了升采样。在第二阶段,大幅增加了数学和代码相关数据的比例,达到约70%。在第三阶段,进一步加入了约10%的合成响应,用于数学、代码和创意写作查询,并将上下文长度从8,192扩展到32,768。通过这一过程,构建了一个包含约25万亿个token的高质量预训练数据集。
后训练阶段
后训练阶段的第一步是SFT。这一阶段的目标是通过高质量的标注数据对预训练模型进行调整,使其更好地适应特定任务的需求。SFT数据集由开源数据和专有数据组成,经过严格的预处理以确保多样性和质量。预处理流程包括去除与评估基准有重叠的数据,排除混合语言或不完整的样本,并限制每个查询的响应数量,以平衡多样性和冗余性。最终,SFT数据集包含约500K个样本,这些样本在训练过程中被打包到最大长度为32,768个token的序列中,以充分利用模型的上下文处理能力。
在微调过程中,小米采用了3×10⁻⁵的恒定学习率和128的批量大小。这种设置旨在确保模型在微调阶段能够稳定地学习到高质量数据中的模式和规律。
RL是MiMo-7B后训练阶段的核心环节,而高质量的训练数据是实现有效强化学习的基础。小米精心整理了一个包含130K数学和编程问题的数据集,这些问题均可以通过基于规则的验证器进行验证,确保了数据的可靠性和可验证性。为了进一步提升数据质量,小米对每个问题进行了详细的清理和难度评估,以确保训练数据的多样性和挑战性。
在数学问题方面,数据集涵盖了从开源数据集到专有竞赛级别的问题。为了防止奖励欺骗,小米采用了基于规则的准确性奖励机制,并通过模型评估过滤掉那些过于简单或难以解决的问题。最终,经过严格筛选的数学训练集包含100K个问题。对于编程问题,同样采用了严格的筛选标准,确保每个问题都包含有效的测试用例,并通过模型验证过滤掉那些无法通过测试的问题。最终,编程训练集包含30K个高质量问题。
在强化学习训练中,MiMo-7B采用了GRPO算法,通过采样一组响应并最大化策略更新的目标函数,有效地优化了模型的策略。团队在原始GRPO算法的基础上,引入了多项创新技术,以进一步提升训练效果。
首先,移除了KL损失,这一改进基于最新的研究成果,证明移除KL损失可以充分发挥策略模型的潜力,同时保持训练的稳定性。还引入了动态采样技术,通过过采样和过滤,确保每个批次中的样本都具有有效的梯度,从而自动调整问题的难度,使模型在整个训练过程中都能保持有效的学习。此外,采用了Clip-Higher方法,通过增加上剪辑边界,缓解了熵收敛问题,并促进了策略探索新的解决方案。

目前,小米的大模型小米刚成立不久,正在招兵买马,有想法的同学可以联系。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






